
Вы когда-нибудь задумывались, как чат-боты и виртуальные помощники просыпаются, когда вы говорите «Привет, Siri» или «Alexa»? Это происходит из-за набора текстовых высказываний или триггерных слов, встроенных в программное обеспечение, которое активирует систему, как только слышит запрограммированное слово пробуждения.
Однако общий процесс создания звуков и данных о высказываниях не так прост. Это процесс, который должен выполняться с правильной техникой, чтобы получить желаемые результаты. Поэтому в этом блоге вы узнаете, как создавать хорошие высказывания/слова-триггеры, которые без проблем работают с вашим разговорным ИИ.
Что такое высказывания?
Высказывания могут называться фразами или триггерными словами, используемыми для активации модели искусственного интеллекта. Когда ваша модель ИИ обнаруживает свое слово пробуждения, она автоматически начинает записывать следующий запрос пользователя и отвечает подходящим действием или ответом.
Utterance использует концепцию глубокого обучения, чтобы научить программное обеспечение распознавать слова пробуждения. Как только слово пробуждения активирует программное обеспечение, система начинает захват, декодирование и обслуживание запроса. Когда система не используется, она пассивно продолжает прослушивать триггерные слова.
Чтобы программное обеспечение искусственного интеллекта выдавало точные результаты, важно фиксировать множество различных высказываний для каждого намерения. Это помогает лучше тренировать модель ИИ.
[Также Читайте: Хотите узнать, как Siri и Alexa вас понимают??]
Что нужно помнить при создании репозитория высказываний
Теперь, когда мы знаем, что обучение важно для моделей ИИ, следующее, что нужно знать, — это как предоставлять высказывания моделям ИИ. Обычно репозиторий высказываний создается для обучения разговорных ИИ.
Однако при создании репозиториев высказываний нужно помнить о разных вещах. Ниже приведены вещи, которые следует учитывать:
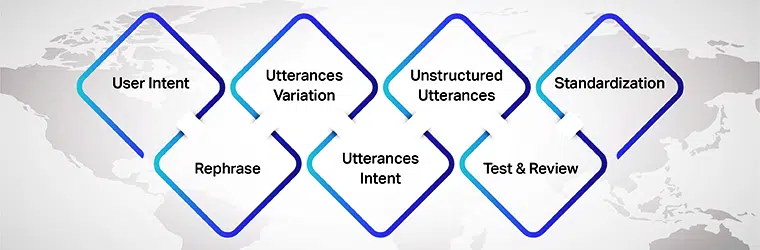
Намерение пользователя
Прежде всего, при подготовке высказываний для вашей модели ИИ убедитесь, что вы понимаете намерение пользователя, для которого вы разрабатываете наборы данных. Вам нужно выяснить различные высказывания, которые пользователи могут вводить во время разговора с моделью ИИ.
Вариация высказываний
Вариации являются неотъемлемой частью этого процесса, так как чем больше вариаций для каждого намерения, тем лучших результатов вы добьетесь. Поэтому обязательно создайте несколько вариантов высказываний пользователя. Вы можете сделать это по
- Составление коротких, средних и больших предложений для одних и тех же предложений.
- Изменение слов и длины предложений.
- Использование уникальных слов.
- Множественное число предложений.
- Перепутал грамматику.



