Введение
 Искусственный интеллект - это использование машин для улучшения жизни и образа жизни людей, делая их повседневную жизнь интересной, а повторяющиеся задачи - простыми. ИИ никогда не должен быть доминирующей силой, но дополняющей силой, которая работает в тандеме с людьми, чтобы разрешить невероятное и проложить путь для коллективной эволюции.
Искусственный интеллект - это использование машин для улучшения жизни и образа жизни людей, делая их повседневную жизнь интересной, а повторяющиеся задачи - простыми. ИИ никогда не должен быть доминирующей силой, но дополняющей силой, которая работает в тандеме с людьми, чтобы разрешить невероятное и проложить путь для коллективной эволюции.
На данный момент мы идем по правильному пути, и в разных отраслях с помощью ИИ происходят значительные прорывы. Если вы возьмете, к примеру, здравоохранение, системы искусственного интеллекта, сопровождаемые моделями машинного обучения, помогают экспертам лучше понять рак и разработать методы его лечения. Неврологические расстройства и проблемы, такие как посттравматическое стрессовое расстройство, лечат с помощью искусственного интеллекта. Вакцины разрабатываются быстрыми темпами благодаря клиническим испытаниям и моделированию на базе искусственного интеллекта.
Не только здравоохранение, но и все отрасли или сегменты, которых касается ИИ, претерпевают революционные изменения. Автономные транспортные средства, интеллектуальные магазины, носимые устройства, такие как FitBit, и даже камеры наших смартфонов могут лучше снимать наши лица с помощью искусственного интеллекта.
Благодаря инновациям, происходящим в области искусственного интеллекта, компании выходят на рынок с различными вариантами использования и решениями. В связи с этим ожидается, что к концу 267 года мировой рынок искусственного интеллекта достигнет рыночной стоимости около 2027 млрд долларов. Кроме того, около 37% предприятий уже внедряют решения на основе искусственного интеллекта в свои процессы и продукты.
Что еще более интересно, почти 77% продуктов и услуг, которые мы используем сегодня, основаны на искусственном интеллекте. Поскольку технологическая концепция значительно набирает обороты по вертикали, как предприятиям удается делать невозможное с помощью ИИ?

 Как такие простые устройства, как часы, точно предсказывают сердечные приступы у людей? Как это возможно, что автомобили, которые всегда требовали водителя, внезапно стали меньше водить по дорогам?
Как такие простые устройства, как часы, точно предсказывают сердечные приступы у людей? Как это возможно, что автомобили, которые всегда требовали водителя, внезапно стали меньше водить по дорогам?
Как чат-боты заставляют нас поверить в то, что мы разговариваем с другим человеком на другой стороне?
Если вы наблюдаете за ответом на каждый вопрос, он сводится к одному элементу - ДАННЫМ. Данные лежат в основе всех операций и процессов, связанных с ИИ. Это данные, которые помогают машинам понимать концепции, входные данные процесса и получать точные результаты.
Все основные решения ИИ, которые существуют, являются продуктами важнейшего процесса, который мы называем сбором данных или сбором данных или данными обучения ИИ.
Это обширное руководство поможет вам понять, что это такое и почему это важно.
Что такое сбор данных AI?
У машин нет собственного разума. Отсутствие этой абстрактной концепции лишает их мнений, фактов и способностей, таких как рассуждение, познание и многое другое. Это просто неподвижные коробки или устройства, занимающие место. Чтобы превратить их в мощные носители, вам нужны алгоритмы и, что более важно, данные.
 Разработанным алгоритмам нужно над чем работать и обрабатывать, и это что-то является актуальными, контекстными и свежими данными. Процесс сбора таких данных для машин для использования по назначению называется сбором данных ИИ.
Разработанным алгоритмам нужно над чем работать и обрабатывать, и это что-то является актуальными, контекстными и свежими данными. Процесс сбора таких данных для машин для использования по назначению называется сбором данных ИИ.
Каждый продукт или решение с поддержкой ИИ, которые мы используем сегодня, и результаты, которые они предлагают, являются результатом многолетнего обучения, разработки и оптимизации. От устройств, предлагающих навигационные маршруты, до сложных систем, которые заранее прогнозируют отказ оборудования за несколько дней, каждая организация прошла годы обучения искусственному интеллекту, чтобы иметь возможность точно предоставлять результаты.
Сбор данных AI — это предварительный шаг в процессе разработки ИИ, который с самого начала определяет, насколько эффективной и действенной будет система ИИ. Это процесс поиска соответствующих наборов данных из множества источников, которые помогут моделям ИИ лучше обрабатывать детали и получать значимые результаты.




Как собирать данные для машинного обучения?
 Здесь все становится немного сложнее. С самого начала могло показаться, что у вас есть решение реальной проблемы, вы знаете, что искусственный интеллект был бы идеальным способом решения этой проблемы, и вы разработали свои модели. Но сейчас вы находитесь в решающей фазе, когда вам нужно начать процессы обучения ИИ. Вам понадобится обширный набор данных для обучения искусственному интеллекту, чтобы ваши модели усваивали концепции и приносили результаты. Вам также нужны данные проверки, чтобы проверить свои результаты и оптимизировать свои алгоритмы.
Здесь все становится немного сложнее. С самого начала могло показаться, что у вас есть решение реальной проблемы, вы знаете, что искусственный интеллект был бы идеальным способом решения этой проблемы, и вы разработали свои модели. Но сейчас вы находитесь в решающей фазе, когда вам нужно начать процессы обучения ИИ. Вам понадобится обширный набор данных для обучения искусственному интеллекту, чтобы ваши модели усваивали концепции и приносили результаты. Вам также нужны данные проверки, чтобы проверить свои результаты и оптимизировать свои алгоритмы.
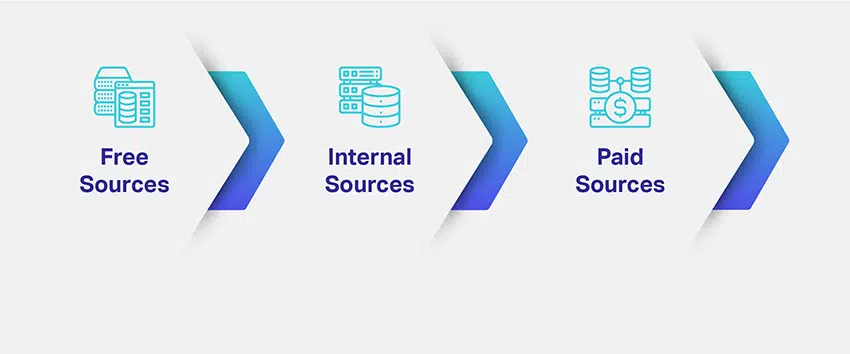
Итак, как вы получаете свои данные? Какие данные вам нужны и в каком количестве? Из каких источников можно получить релевантные данные?
Компании оценивают нишу и цель своих моделей машинного обучения и намечают потенциальные способы получения соответствующих наборов данных. Определение необходимого типа данных решает основную часть вашей проблемы с источниками данных. Чтобы дать вам лучшее представление, существуют разные каналы, пути, источники или среды для сбора данных:
Как плохие данные влияют на ваши амбиции в области ИИ?
Мы перечислили три наиболее распространенных ресурса данных, чтобы у вас было представление о том, как подходить к сбору данных и их источникам. Однако на этом этапе становится важным также понимать, что ваше решение неизменно может решить судьбу вашего ИИ-решения.
Подобно тому, как высококачественные данные обучения ИИ могут помочь вашей модели предоставлять точные и своевременные результаты, плохие данные обучения также могут нарушить ваши модели ИИ, исказить результаты, внести систематическую ошибку и привести к другим нежелательным последствиям.
Но почему это происходит? Разве какие-либо данные не предназначены для обучения и оптимизации вашей модели ИИ? Честно говоря, нет. Давайте разбираться в этом дальше.
Плохие данные - что это?
 Плохие данные — это любые данные, которые являются нерелевантными, неверными, неполными или предвзятыми. Благодаря плохо определенным стратегиям сбора данных, большинство специалистов по данным и эксперты по аннотациям вынуждены работать с неверными данными.
Плохие данные — это любые данные, которые являются нерелевантными, неверными, неполными или предвзятыми. Благодаря плохо определенным стратегиям сбора данных, большинство специалистов по данным и эксперты по аннотациям вынуждены работать с неверными данными.
Разница между неструктурированными и неверными данными заключается в том, что понимание неструктурированных данных находится повсюду. Но по сути, они могут быть полезны в любом случае. Потратив дополнительное время, специалисты по данным все равно смогут извлекать релевантную информацию из неструктурированных наборов данных. Однако с плохими данными дело обстоит иначе. Эти наборы данных не содержат / не содержат аналитических сведений или информации, которая имеет ценность или имеет отношение к вашему проекту ИИ или его учебным целям.
Таким образом, когда вы получаете наборы данных из бесплатных ресурсов или имеете слабо установленные внутренние точки соприкосновения с данными, высока вероятность того, что вы загрузите или сгенерируете неверные данные. Когда ваши ученые работают с неверными данными, вы не только тратите зря человеческие часы, но и ускоряете запуск своего продукта.
Если вам все еще неясно, что плохие данные могут повлиять на ваши амбиции, вот краткий список:
- Вы тратите бесчисленные часы на поиск неверных данных и тратите время, силы и деньги на ресурсы.
- Плохие данные могут вызвать проблемы с законом, если они останутся незамеченными, и могут снизить эффективность вашего ИИ.
модели. - Когда вы обучаете свой продукт работе с неверными данными, это влияет на взаимодействие с пользователем.
- Плохие данные могут сделать результаты и выводы необъективными, что может вызвать негативную реакцию.
Итак, если вам интересно, есть ли решение для этого, на самом деле оно есть.
Поставщики данных для обучения ИИ спешат на помощь
 Одно из основных решений - обратиться к поставщику данных (платные источники). Поставщики данных для обучения искусственного интеллекта обеспечивают точность и актуальность получаемой вами информации, а также предоставление вам наборов данных в структурированной форме. Вам не нужно участвовать в хлопотах, связанных с переходом от портала к порталу в поисках наборов данных.
Одно из основных решений - обратиться к поставщику данных (платные источники). Поставщики данных для обучения искусственного интеллекта обеспечивают точность и актуальность получаемой вами информации, а также предоставление вам наборов данных в структурированной форме. Вам не нужно участвовать в хлопотах, связанных с переходом от портала к порталу в поисках наборов данных.
Все, что вам нужно сделать, это собрать данные и довести до совершенства свои модели искусственного интеллекта. С учетом сказанного, мы уверены, что ваш следующий вопрос будет о расходах, связанных с сотрудничеством с поставщиками данных. Мы понимаем, что некоторые из вас уже работают над ментальным бюджетом, и именно к этому мы и направляемся в следующий раз.
Факторы, которые следует учитывать при составлении эффективного бюджета для вашего проекта по сбору данных
Обучение искусственному интеллекту - это системный подход, поэтому составление бюджета становится его неотъемлемой частью. Прежде чем вкладывать огромные деньги в разработку ИИ, следует учитывать такие факторы, как RoI, точность результатов, методики обучения и многое другое. На этом этапе многие руководители проектов или владельцы бизнеса теряются. Они принимают поспешные решения, которые вносят необратимые изменения в процесс разработки продукта, в конечном итоге вынуждая их тратить больше.
Однако этот раздел даст вам правильную информацию. Когда вы садитесь работать над бюджетом на обучение ИИ, неизбежны три вещи или фактора.

Давайте рассмотрим каждую подробно.
Объем необходимых вам данных
Мы все время говорили, что эффективность и точность вашей модели ИИ зависит от того, насколько она обучена. Это означает, что чем больше объем наборов данных, тем больше обучения. Но это очень расплывчато. Чтобы прояснить это понятие, Dimensional Research опубликовала отчет, в котором выяснилось, что компаниям необходимо как минимум 100,000 XNUMX образцов данных для обучения своих моделей искусственного интеллекта.
Под 100,000 100,000 наборов данных мы подразумеваем XNUMX XNUMX качественных и релевантных наборов данных. Эти наборы данных должны иметь все необходимые атрибуты, аннотации и аналитические данные, необходимые для ваших алгоритмов и моделей машинного обучения для обработки информации и выполнения намеченных задач.
Имея это общее практическое правило, давайте также поймем, что объем необходимых вам данных также зависит от другого сложного фактора, который является вариантом использования вашего бизнеса. То, что вы собираетесь делать со своим продуктом или решением, также решает, сколько данных вам нужно. Например, компания, создающая механизм рекомендаций, будет иметь другие требования к объему данных, чем компания, которая создает чат-бота.
Стратегия ценообразования данных
Когда вы закончите определение того, сколько данных вам действительно нужно, вам нужно будет работать над стратегией ценообразования данных. Проще говоря, это означает, как вы будете платить за наборы данных, которые вы приобретаете или генерируете.
В общем, это обычные стратегии ценообразования, которых придерживаются на рынке:
| Тип данных | Стратегия ценообразования |
|---|---|
| Цена за один файл изображения | |
| Цена за секунду, минуту, час или отдельный кадр. | |
| Цена за секунду, минуту или час | |
| Цена за слово или предложение |
Но ждать. Это снова практическое правило. Фактическая стоимость приобретения наборов данных также зависит от таких факторов, как:
- Уникальный сегмент рынка, демографические данные или география, откуда должны быть получены наборы данных
- Сложность вашего варианта использования
- Сколько данных вам нужно?
- Ваше время для выхода на рынок
- Любые индивидуальные требования и многое другое
Если вы заметите, то узнаете, что стоимость приобретения большого количества изображений для вашего проекта AI может быть меньше, но если у вас слишком много спецификаций, цены могут резко вырасти.
Ваши стратегии поиска поставщиков
Это сложно. Как вы видели, существуют разные способы генерации или источника данных для ваших моделей ИИ. Здравый смысл подсказывает, что бесплатные ресурсы являются лучшими, поскольку вы можете бесплатно загружать необходимые объемы наборов данных без каких-либо осложнений.
Прямо сейчас может показаться, что платные источники слишком дороги. Но здесь добавляется еще один уровень сложности. Когда вы получаете наборы данных из бесплатных ресурсов, вы тратите дополнительное количество времени и усилий на очистку своих наборов данных, компиляцию их в формат для вашего бизнеса, а затем аннотирование их по отдельности. При этом вы несете операционные расходы.
При использовании платных источников оплата является единовременной, и вы также получаете готовые для машины наборы данных в нужное время. Рентабельность здесь очень субъективна. Если вы чувствуете, что можете позволить себе тратить время на аннотирование бесплатных наборов данных, вы можете внести соответствующий бюджет. И если вы считаете, что ваша конкуренция жесткая и у вас ограниченное время выхода на рынок, вы можете создать волновой эффект на рынке, вам следует предпочесть платные источники.
Бюджетирование - это разбивка деталей и четкое определение каждого фрагмента. Эти три фактора должны послужить вам дорожной картой для вашего процесса составления бюджета на обучение ИИ в будущем.
Вы экономите на сборе данных внутри компании?
 При составлении бюджета мы исследовали, как бесплатные ресурсы заставляют вас тратить больше в долгосрочной перспективе. В этот момент вы бы автоматически задумались о рентабельности внутреннего процесса сбора данных.
При составлении бюджета мы исследовали, как бесплатные ресурсы заставляют вас тратить больше в долгосрочной перспективе. В этот момент вы бы автоматически задумались о рентабельности внутреннего процесса сбора данных.
Мы знаем, что вы все еще сомневаетесь в выборе платных источников, и поэтому этот раздел развеет ваш скептицизм по этому поводу и прольет свет на скрытые затраты, связанные с внутренним генерированием данных.
Дорогой ли сбор данных внутри компании?
Да, это!
А теперь подробный ответ. Расходы - это все, что вы тратите. Обсуждая бесплатные ресурсы, мы выяснили, что вы тратите деньги, время и усилия. Это также относится к внутреннему сбору данных.
 Тот факт, что у вас есть настраиваемые точки взаимодействия или воронки данных, не означает, что вы должны готовые наборы данных в конце. Генерируемые вами данные по-прежнему будут в основном необработанными и неструктурированными. У вас могут быть все необходимые данные в одном месте, но то, что они содержат, будет повсюду.
Тот факт, что у вас есть настраиваемые точки взаимодействия или воронки данных, не означает, что вы должны готовые наборы данных в конце. Генерируемые вами данные по-прежнему будут в основном необработанными и неструктурированными. У вас могут быть все необходимые данные в одном месте, но то, что они содержат, будет повсюду.
В конечном итоге вы потратите деньги на оплату труда своих сотрудников, специалистов по обработке данных, аннотаторов, специалистов по обеспечению качества и многого другого. Вы также будете тратить на подписку на инструменты аннотации и
расходы на обслуживание CMS, CRM и другой инфраструктуры.
Кроме того, наборы данных обязательно должны иметь проблемы смещения и точности, которые вам необходимо вручную отсортировать. И если у вас есть проблема с истощением в вашей команде данных по обучению ИИ, вам придется потратиться на набор новых членов, ориентацию их на ваши процессы, обучение их использованию ваших инструментов и многое другое.
В конечном итоге вы потратите больше, чем в конечном итоге заработали бы в долгосрочной перспективе. Также есть расходы на аннотации. В любой момент времени общие затраты на работу с внутренними данными составляют:
Затраты = количество аннотаторов * стоимость аннотатора + стоимость платформы
Если ваш календарь тренировок ИИ рассчитан на месяцы, представьте, какие расходы вы будете постоянно нести. Итак, является ли это идеальным решением проблем сбора данных или есть какая-то альтернатива?
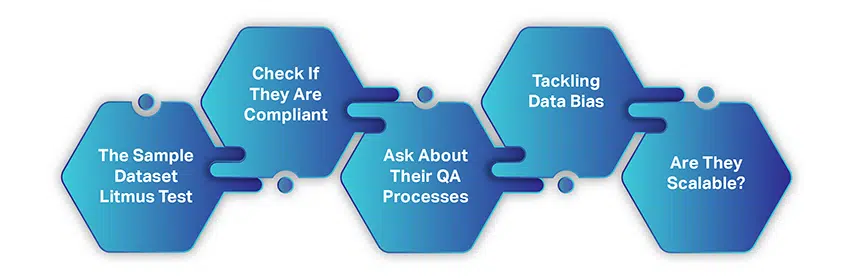
Как выбрать подходящую компанию по сбору данных AI
Выбор компании по сбору данных AI не такой сложный или трудоемкий, как сбор данных из бесплатных ресурсов. Есть только несколько простых факторов, которые вам нужно рассмотреть, а затем пожать друг другу руки для сотрудничества.
Когда вы начинаете искать поставщика данных, мы предполагаем, что вы следовали и учли все, что мы обсуждали до сих пор. Однако вот краткое резюме:
- У вас есть четко определенный вариант использования
- Ваш сегмент рынка и требования к данным четко определены
- Ваш бюджет в порядке
- И у вас есть представление о том, какой объем данных вам нужен
Отметив эти пункты, давайте разберемся, как вы можете найти идеального поставщика услуг по обучению.