
Введение
Это руководство будет чрезвычайно полезно для тех покупателей и лиц, принимающих решения, которые начинают обращать свои мысли к основам поиска и реализации данных как для нейронных сетей, так и для других типов операций AI и ML.

Эта статья полностью посвящена тому, чтобы пролить свет на то, что это за процесс, почему он неизбежен, важен.
факторы, которые компании должны учитывать при использовании инструментов аннотации данных и т. д. Итак, если у вас есть бизнес, подготовьтесь к тому, чтобы получить знания, поскольку это руководство проведет вас через все, что вам нужно знать об аннотации данных.
Итак, начнем.
Для тех из вас, кто бегло просматривает статью, вот несколько быстрых выводов, которые вы найдете в руководстве:
- Понять, что такое аннотация к данным
- Знать различные типы процессов аннотации данных
- Знать преимущества внедрения процесса аннотации данных
- Получите четкое представление о том, следует ли вам использовать собственную маркировку данных или отдать ее на аутсорсинг.
- Полезные советы по выбору подходящей аннотации к данным
Что такое машинное обучение?
 Мы говорили о том, как аннотации данных или маркировка данных поддерживает машинное обучение и состоит из маркировки или идентификации компонентов. Но что касается глубокого обучения и самого машинного обучения: основная предпосылка машинного обучения заключается в том, что компьютерные системы и программы могут улучшать свои результаты способами, которые напоминают человеческие когнитивные процессы, без прямой помощи или вмешательства человека, чтобы дать нам понимание. Другими словами, они становятся самообучающимися машинами, которые, как и люди, становятся лучше в своей работе с большей практикой. Эта «практика» достигается за счет анализа и интерпретации большего количества (и более качественных) данных обучения.
Мы говорили о том, как аннотации данных или маркировка данных поддерживает машинное обучение и состоит из маркировки или идентификации компонентов. Но что касается глубокого обучения и самого машинного обучения: основная предпосылка машинного обучения заключается в том, что компьютерные системы и программы могут улучшать свои результаты способами, которые напоминают человеческие когнитивные процессы, без прямой помощи или вмешательства человека, чтобы дать нам понимание. Другими словами, они становятся самообучающимися машинами, которые, как и люди, становятся лучше в своей работе с большей практикой. Эта «практика» достигается за счет анализа и интерпретации большего количества (и более качественных) данных обучения.
Что такое аннотация к данным?
Аннотирование данных — это процесс атрибутирования, тегирования или маркировки данных, помогающий алгоритмам машинного обучения понимать и классифицировать обрабатываемую ими информацию. Этот процесс необходим для обучения моделей ИИ, позволяя им точно понимать различные типы данных, такие как изображения, аудиофайлы, видеоматериалы или текст.
Представьте себе беспилотный автомобиль, который опирается на данные компьютерного зрения, обработки естественного языка (NLP) и датчиков для принятия точных решений о вождении. Чтобы модель ИИ автомобиля могла различать препятствия, такие как другие транспортные средства, пешеходы, животные или блокпосты, полученные данные должны быть помечены или аннотированы.
В обучении с учителем аннотация данных особенно важна, так как чем больше помеченных данных подается в модель, тем быстрее она учится функционировать автономно. Аннотированные данные позволяют развертывать модели ИИ в различных приложениях, таких как чат-боты, распознавание речи и автоматизация, что обеспечивает оптимальную производительность и надежные результаты.
Что такое инструмент для маркировки / аннотации данных?
 Проще говоря, это платформа или портал, позволяющий специалистам и экспертам комментировать, маркировать или маркировать наборы данных всех типов. Это мост или посредник между необработанными данными и результатами, которые в конечном итоге получат ваши модули машинного обучения.
Проще говоря, это платформа или портал, позволяющий специалистам и экспертам комментировать, маркировать или маркировать наборы данных всех типов. Это мост или посредник между необработанными данными и результатами, которые в конечном итоге получат ваши модули машинного обучения.
Инструмент маркировки данных - это локальное или облачное решение, которое аннотирует высококачественные данные обучения для моделей машинного обучения. Хотя многие компании полагаются на внешних поставщиков для составления сложных аннотаций, некоторые организации по-прежнему имеют свои собственные инструменты, которые либо созданы на заказ, либо основаны на бесплатных или открытых инструментах, доступных на рынке. Такие инструменты обычно предназначены для обработки определенных типов данных, например изображения, видео, текста, звука и т. Д. Инструменты предлагают функции или параметры, такие как ограничивающие прямоугольники или многоугольники для аннотаторов данных для маркировки изображений. Они могут просто выбрать вариант и выполнить свои конкретные задачи.
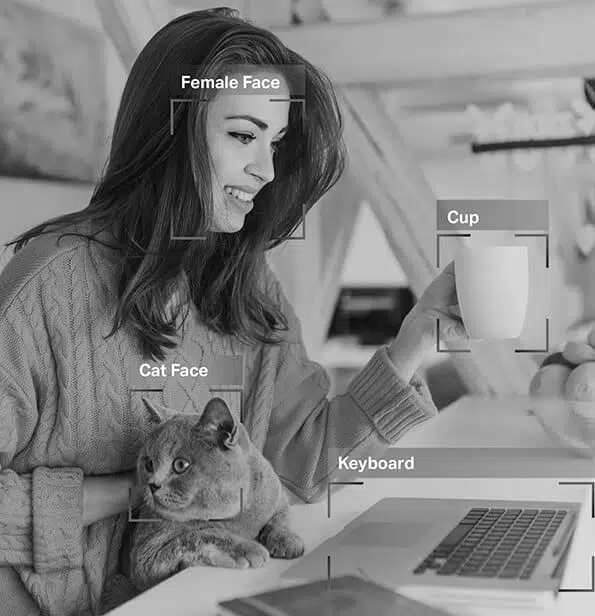
Аннотация изображения

Из наборов данных, которым они обучены, они могут мгновенно и точно отличить ваши глаза от носа и брови от ресниц. Вот почему применяемые фильтры идеально подходят независимо от формы вашего лица, того, насколько близко вы находитесь к камере и т. Д.
Итак, как вы теперь знаете, аннотация изображения жизненно важен для модулей, включающих распознавание лиц, компьютерное зрение, зрение роботов и многое другое. Когда эксперты ИИ обучают такие модели, они добавляют подписи, идентификаторы и ключевые слова в качестве атрибутов к своим изображениям. Затем алгоритмы идентифицируют и понимают эти параметры и учатся автономно.
Классификация изображений – Классификация изображений включает в себя назначение предопределенных категорий или меток изображениям на основе их содержимого. Этот тип аннотаций используется для обучения моделей ИИ автоматическому распознаванию и классификации изображений.
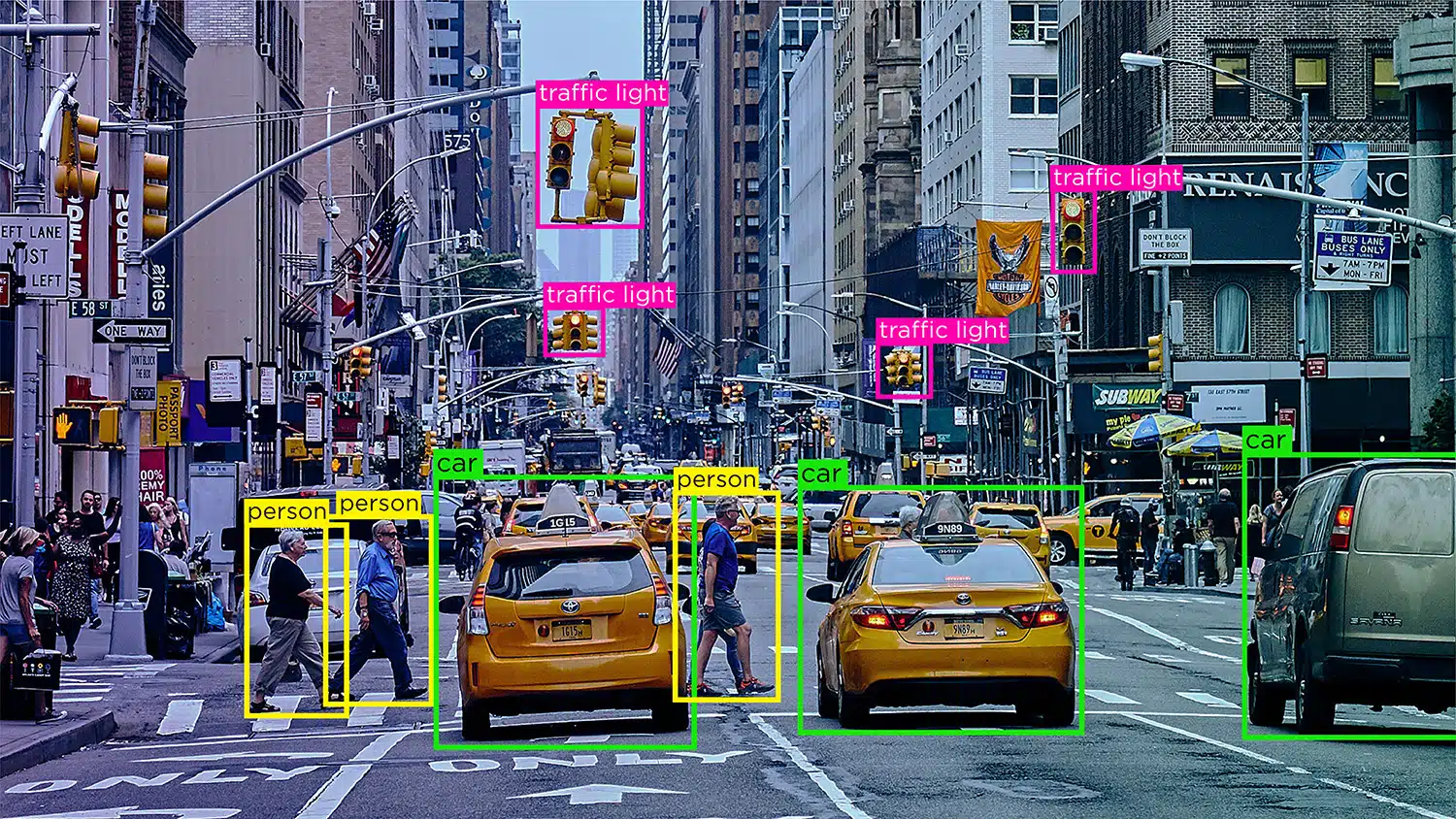
Распознавание/обнаружение объектов – Распознавание объектов или обнаружение объектов — это процесс идентификации и маркировки определенных объектов на изображении. Этот тип аннотаций используется для обучения моделей ИИ нахождению и распознаванию объектов на реальных изображениях или видео.
Сегментация – Сегментация изображения включает в себя разделение изображения на несколько сегментов или областей, каждая из которых соответствует определенному объекту или интересующей области. Этот тип аннотаций используется для обучения моделей ИИ анализу изображений на уровне пикселей, что обеспечивает более точное распознавание объектов и понимание сцены.
Аудио аннотация
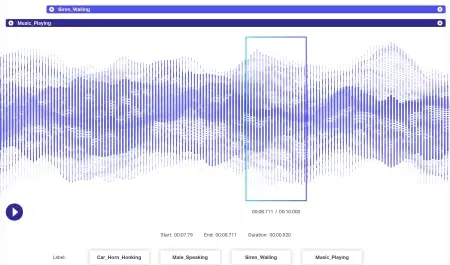
Аудиоданные имеют даже больше динамики, чем данные изображения. С аудиофайлом связано несколько факторов, включая, помимо прочего, язык, демографические данные говорящего, диалекты, настроение, намерения, эмоции, поведение. Чтобы алгоритмы были эффективными при обработке, все эти параметры должны быть идентифицированы и помечены такими методами, как временные метки, звуковые метки и т. Д. Помимо просто словесных сигналов, невербальные примеры, такие как тишина, дыхание, даже фоновый шум, могут быть аннотированы для системного понимания.
Видеоаннотации

Пока изображение неподвижно, видео представляет собой набор изображений, создающих эффект движения объектов. Теперь каждое изображение в этой компиляции называется кадром. Что касается видеоаннотаций, процесс включает добавление ключевых точек, многоугольников или ограничивающих рамок для аннотирования различных объектов в поле в каждом кадре.
Когда эти кадры сшиваются вместе, модели ИИ в действии могут изучать движение, поведение, шаблоны и многое другое. это только через аннотация к видео что такие концепции, как локализация, размытие движения и отслеживание объектов, могут быть реализованы в системах.
Текстовая аннотация

Сегодня большинство предприятий полагаются на текстовые данные для получения уникальных сведений и информации. Теперь текст может быть чем угодно, от отзывов клиентов о приложении до упоминания в социальных сетях. И в отличие от изображений и видео, которые в основном передают прямые намерения, текст обладает большой семантикой.
Как люди, мы настроены на понимание контекста фразы, значения каждого слова, предложения или фразы, соотносим их с определенной ситуацией или беседой, а затем осознаем целостный смысл утверждения. Машины же не могут делать это на точных уровнях. Такие понятия, как сарказм, юмор и другие абстрактные элементы им неизвестны, и поэтому разметка текстовых данных становится более сложной. Вот почему текстовая аннотация имеет несколько более тонких этапов, таких как следующие:
Семантическая аннотация - объекты, продукты и услуги становятся более актуальными с помощью соответствующих параметров тегирования и идентификации по ключевым словам. Чат-боты также созданы таким образом, чтобы имитировать человеческие разговоры.
Аннотация намерения - намерение пользователя и используемый им язык помечены тегами, чтобы машины могли их понять. Благодаря этому модели могут отличать запрос от команды, рекомендацию от бронирования и т. Д.
Аннотация настроений – Аннотация настроений включает в себя маркировку текстовых данных настроением, которое они передают, например положительным, отрицательным или нейтральным. Этот тип аннотаций обычно используется при анализе настроений, когда модели ИИ обучаются понимать и оценивать эмоции, выраженные в тексте.

Аннотация объекта - где неструктурированные предложения помечены тегами, чтобы сделать их более значимыми и привести их в формат, понятный машинам. Чтобы это произошло, задействованы два аспекта: признание именованного объекта и соединение сущностей. Распознавание именованных объектов - это когда названия мест, людей, событий, организаций и т. Д. Помечаются и идентифицируются, а связывание объектов - это когда эти теги связаны с предложениями, фразами, фактами или мнениями, которые следуют за ними. В совокупности эти два процесса устанавливают отношения между ассоциированными текстами и окружающим их утверждением.
Категоризация текста - Предложения или абзацы могут быть помечены и классифицированы на основе общих тем, тенденций, тем, мнений, категорий (спорт, развлечения и т. д.) и других параметров.
Ключевые этапы процесса маркировки данных и аннотирования данных
Процесс аннотирования данных включает в себя ряд четко определенных шагов для обеспечения высококачественной и точной маркировки данных для приложений машинного обучения. Эти шаги охватывают все аспекты процесса, от сбора данных до экспорта аннотированных данных для дальнейшего использования.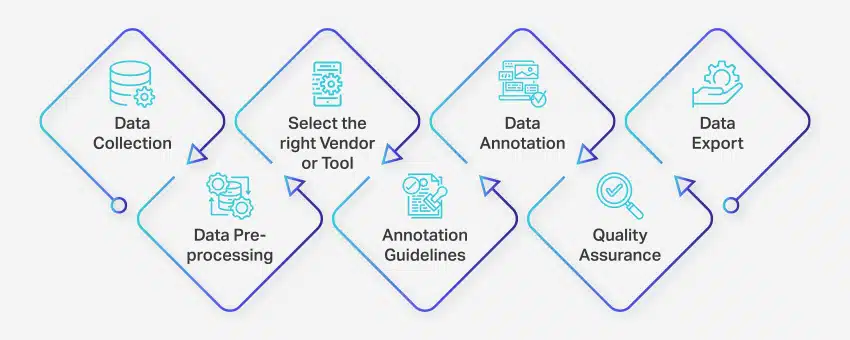
Вот как происходит аннотация данных:
- Сбор данных: Первым шагом в процессе аннотирования данных является сбор всех соответствующих данных, таких как изображения, видео, аудиозаписи или текстовые данные, в централизованном месте.
- Предварительная обработка данных: Стандартизируйте и улучшайте собранные данные, выравнивая изображения, форматируя текст или расшифровывая видеоконтент. Предварительная обработка гарантирует, что данные готовы для аннотирования.
- Выберите подходящего поставщика или инструмент: Выберите подходящий инструмент для аннотирования данных или поставщика в зависимости от требований вашего проекта. Варианты включают такие платформы, как Nanonets для аннотаций данных, V7 для аннотаций изображений, Appen для аннотаций видео и Nanonets для аннотаций документов.
- Руководство по аннотации: Установите четкие рекомендации для аннотаторов или инструментов аннотирования, чтобы обеспечить согласованность и точность на протяжении всего процесса.
- Аннотация: Маркируйте и помечайте данные с помощью аннотаторов-людей или программного обеспечения для аннотирования данных, следуя установленным правилам.
- Обеспечение качества (ОК): Просмотрите аннотированные данные, чтобы убедиться в их точности и согласованности. При необходимости используйте несколько слепых аннотаций, чтобы проверить качество результатов.
- Экспорт данных: После завершения аннотации данных экспортируйте данные в требуемом формате. Такие платформы, как Nanonets, обеспечивают беспрепятственный экспорт данных в различные бизнес-приложения.
Весь процесс аннотирования данных может занять от нескольких дней до нескольких недель, в зависимости от размера проекта, сложности и доступных ресурсов.
Функции для инструментов аннотации и маркировки данных
Инструменты аннотации данных - решающие факторы, которые могут сделать или сломать ваш проект AI. Когда дело доходит до точных выходных данных и результатов, само по себе качество наборов данных не имеет значения. Фактически, инструменты аннотации данных, которые вы используете для обучения своих модулей ИИ, очень сильно влияют на ваши результаты.
Вот почему так важно выбрать и использовать наиболее функциональный и подходящий инструмент маркировки данных, который соответствует потребностям вашего бизнеса или проекта. Но что такое инструмент аннотации данных в первую очередь? Какой цели это служит? Есть ли типы? Что ж, давайте узнаем.
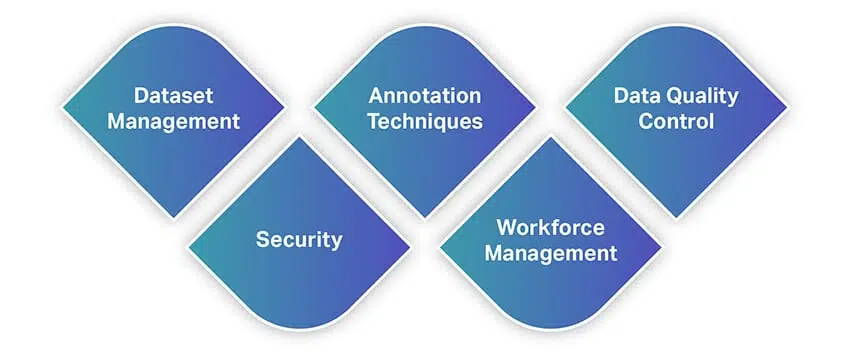
Подобно другим инструментам, инструменты аннотации данных предлагают широкий спектр функций и возможностей. Чтобы дать вам быстрое представление о функциях, вот список некоторых из наиболее фундаментальных функций, на которые следует обратить внимание при выборе инструмента для аннотации данных.
Управление наборами данных
Инструмент аннотации данных, который вы собираетесь использовать, должен поддерживать имеющиеся у вас наборы данных и позволять вам импортировать их в программное обеспечение для маркировки. Итак, управление вашими наборами данных - это основное предложение функциональных инструментов. Современные решения предлагают функции, которые позволяют беспрепятственно импортировать большие объемы данных, одновременно позволяя организовывать наборы данных с помощью таких действий, как сортировка, фильтрация, клонирование, объединение и многое другое.
После ввода ваших наборов данных выполняется их экспорт в виде файлов, пригодных для использования. Инструмент, который вы используете, должен позволять вам сохранять ваши наборы данных в указанном вами формате, чтобы вы могли загружать их в свои модели машинного обучения.
Аннотации
Это то, для чего создан или разработан инструмент для аннотации данных. Надежный инструмент должен предлагать вам ряд методов аннотации для наборов данных всех типов. Это если вы не разрабатываете индивидуальное решение для своих нужд. Ваш инструмент должен позволять вам комментировать видео или изображения из компьютерного зрения, аудио или текст из НЛП, а также транскрипции и многое другое. Усовершенствуя это дальше, должны быть варианты использования ограничивающих рамок, семантической сегментации, кубоидов, интерполяции, анализа тональности, частей речи, решения кореферентности и многого другого.
Для непосвященных также есть инструменты аннотации данных на базе искусственного интеллекта. Они поставляются с модулями ИИ, которые автономно учатся на шаблонах работы аннотатора и автоматически аннотируют изображения или текст. Такой
модули могут быть использованы для оказания невероятной помощи аннотаторам, оптимизации аннотаций и даже реализации проверки качества.
Контроль качества данных
Говоря о проверках качества, несколько инструментов аннотации данных развертываются со встроенными модулями проверки качества. Это позволяет комментаторам лучше сотрудничать с членами своей команды и помогает оптимизировать рабочие процессы. С помощью этой функции аннотаторы могут отмечать и отслеживать комментарии или отзывы в режиме реального времени, отслеживать личности людей, которые вносят изменения в файлы, восстанавливать предыдущие версии, выбирать маркировку консенсуса и многое другое.
Безопасность
Поскольку вы работаете с данными, безопасность должна быть наивысшим приоритетом. Возможно, вы работаете с конфиденциальными данными, например, с личными данными или интеллектуальной собственностью. Таким образом, ваш инструмент должен обеспечивать надежную защиту с точки зрения того, где хранятся данные и как они передаются. Он должен предоставлять инструменты, которые ограничивают доступ для членов команды, предотвращают несанкционированные загрузки и многое другое.
Помимо этого, должны соблюдаться стандарты и протоколы безопасности.
Управление персоналом
Инструмент аннотации данных также является своего рода платформой управления проектами, где задачи могут быть назначены членам команды, возможна совместная работа, возможны проверки и многое другое. Вот почему ваш инструмент должен вписываться в ваш рабочий процесс и процесс для повышения производительности.
Кроме того, инструмент также должен иметь минимальную кривую обучения, поскольку процесс аннотации данных сам по себе занимает много времени. Нет смысла тратить слишком много времени на простое изучение инструмента. Таким образом, он должен быть интуитивно понятным и беспрепятственным, чтобы любой мог быстро приступить к работе.
Каковы преимущества аннотации данных?
Аннотации данных имеют решающее значение для оптимизации систем машинного обучения и улучшения взаимодействия с пользователем. Вот некоторые ключевые преимущества аннотации данных:
- Улучшенная эффективность обучения: Маркировка данных помогает лучше обучать модели машинного обучения, повышая общую эффективность и обеспечивая более точные результаты.
- Повышенная точность: Точные аннотированные данные гарантируют, что алгоритмы могут адаптироваться и эффективно обучаться, что приведет к более высокому уровню точности в будущих задачах.
- Снижение человеческого вмешательства: Усовершенствованные инструменты аннотирования данных значительно снижают потребность в ручном вмешательстве, оптимизируя процессы и сокращая связанные с ними расходы.
Таким образом, аннотация данных способствует созданию более эффективных и точных систем машинного обучения, сводя при этом к минимуму затраты и ручные усилия, традиционно необходимые для обучения моделей ИИ.
Создавать или не создавать инструмент аннотации данных
Одна критическая и всеобъемлющая проблема, которая может возникнуть во время проекта аннотации данных или маркировки данных, - это выбор либо создать, либо купить функциональность для этих процессов. Это может повторяться несколько раз на разных этапах проекта или относиться к разным сегментам программы. При выборе того, создавать ли систему внутри компании или полагаться на поставщиков, всегда есть компромисс.

Как вы, вероятно, теперь можете сказать, аннотации данных - сложный процесс. В то же время это тоже субъективный процесс. Это означает, что нет однозначного ответа на вопрос, стоит ли вам покупать или создавать инструмент для аннотации данных. Необходимо учитывать множество факторов, и вам нужно задать себе несколько вопросов, чтобы понять свои требования и понять, действительно ли вам нужно купить или построить один.
Вот несколько факторов, которые вам следует учитывать.
Ваша цель
Первый элемент, который вам нужно определить, - это цель с вашими концепциями искусственного интеллекта и машинного обучения.
- Почему вы внедряете их в свой бизнес?
- Решают ли они реальную проблему, с которой сталкиваются ваши клиенты?
- Они создают интерфейс или бэкэнд?
- Будете ли вы использовать ИИ для внедрения новых функций или оптимизации существующего веб-сайта, приложения или модуля?
- Что делает ваш конкурент в вашем сегменте?
- Достаточно ли у вас вариантов использования, требующих вмешательства ИИ?
Ответы на них соберут ваши мысли - которые в настоящее время могут быть повсюду - в одно место и дадут вам больше ясности.
Сбор данных AI / лицензирование
Для работы моделей ИИ требуется только один элемент - данные. Вам необходимо определить, откуда вы можете генерировать огромные объемы достоверных данных. Если ваш бизнес генерирует большие объемы данных, которые необходимо обрабатывать для получения важной информации о бизнесе, операциях, исследованиях конкурентов, анализе волатильности рынка, изучении поведения клиентов и т. Д., Вам нужен инструмент аннотации данных. Однако вы также должны учитывать объем генерируемых вами данных. Как упоминалось ранее, эффективность модели искусственного интеллекта зависит от качества и количества передаваемых данных. Так что ваши решения обязательно должны зависеть от этого фактора.
Если у вас нет нужных данных для обучения моделей машинного обучения, поставщики могут оказаться весьма кстати, помогая вам с лицензированием данных для правильного набора данных, необходимых для обучения моделей машинного обучения. В некоторых случаях часть ценности, которую приносит поставщик, будет включать как техническое мастерство, так и доступ к ресурсам, которые будут способствовать успеху проекта.
Бюджет
Еще одно фундаментальное условие, которое, вероятно, влияет на каждый фактор, который мы сейчас обсуждаем. Решение вопроса о том, стоит ли вам создавать или покупать аннотацию к данным, становится легко, если вы понимаете, достаточно ли у вас бюджета для расходов.
Сложности соблюдения
 Поставщики могут быть чрезвычайно полезны, когда речь идет о конфиденциальности данных и правильном обращении с конфиденциальными данными. Один из этих вариантов использования связан с больницей или бизнесом, связанным со здравоохранением, который хочет использовать возможности машинного обучения, не подвергая опасности свое соответствие HIPAA и другим правилам конфиденциальности данных. Даже вне области медицины законы, такие как Европейский GDPR, ужесточают контроль над наборами данных и требуют большей бдительности со стороны корпоративных заинтересованных сторон.
Поставщики могут быть чрезвычайно полезны, когда речь идет о конфиденциальности данных и правильном обращении с конфиденциальными данными. Один из этих вариантов использования связан с больницей или бизнесом, связанным со здравоохранением, который хочет использовать возможности машинного обучения, не подвергая опасности свое соответствие HIPAA и другим правилам конфиденциальности данных. Даже вне области медицины законы, такие как Европейский GDPR, ужесточают контроль над наборами данных и требуют большей бдительности со стороны корпоративных заинтересованных сторон.
Рабочая сила
Для работы с аннотациями к данным требуются квалифицированные кадры, независимо от размера, масштаба и сферы деятельности вашего бизнеса. Даже если вы генерируете минимум данных каждый день, вам нужны эксперты по данным, которые будут работать с вашими данными для маркировки. Итак, теперь вам нужно понять, есть ли у вас необходимая рабочая сила. Если да, то владеют ли они необходимыми инструментами и методами или им нужно повышать квалификацию? Если они нуждаются в повышении квалификации, есть ли у вас средства на их обучение в первую очередь?
Более того, лучшие программы аннотации и маркировки данных берут ряд экспертов в предметной или предметной области и сегментируют их по демографическим данным, таким как возраст, пол и область знаний, или часто с точки зрения локализованных языков, с которыми они будут работать. И снова здесь мы в Shaip говорим о том, чтобы привлечь нужных людей на нужные места, тем самым управляя правильными процессами с участием человека в цикле, которые приведут ваши программные усилия к успеху.
Операции малых и крупных проектов и пороговые значения затрат
Во многих случаях поддержка поставщика может быть более подходящим вариантом для небольшого проекта или для небольших этапов проекта. Когда затраты поддаются контролю, компания может извлечь выгоду из аутсорсинга, чтобы сделать проекты аннотации данных или маркировки данных более эффективными.
Компании также могут следить за важными пороговыми значениями, когда многие поставщики связывают стоимость с объемом потребляемых данных или другими показателями ресурсов. Например, предположим, что компания подписалась на поставщика для выполнения утомительного ввода данных, необходимых для настройки наборов тестов.
В соглашении может быть скрытый порог, когда, например, деловой партнер должен извлечь другой блок хранилища данных AWS или какой-либо другой компонент службы из Amazon Web Services или другого стороннего поставщика. Они передают это покупателю в виде более высоких затрат, и это делает цену недоступной для покупателя.
В этих случаях учет услуг, которые вы получаете от поставщиков, помогает сохранить доступность проекта. Наличие правильного объема гарантирует, что затраты на проект не превысят разумных или выполнимых для данной фирмы.
Альтернативы с открытым исходным кодом и бесплатные программы
 Некоторые альтернативы полной поддержке поставщика включают использование программного обеспечения с открытым исходным кодом или даже бесплатного программного обеспечения для выполнения проектов аннотации данных или маркировки. Здесь есть своего рода золотая середина, когда компании не создают все с нуля, но также избегают слишком сильно полагаться на коммерческих поставщиков.
Некоторые альтернативы полной поддержке поставщика включают использование программного обеспечения с открытым исходным кодом или даже бесплатного программного обеспечения для выполнения проектов аннотации данных или маркировки. Здесь есть своего рода золотая середина, когда компании не создают все с нуля, но также избегают слишком сильно полагаться на коммерческих поставщиков.
Менталитет открытого исходного кода «сделай сам» сам по себе является своего рода компромиссом: инженеры и внутренние люди могут воспользоваться преимуществами сообщества разработчиков открытого исходного кода, где децентрализованные пользовательские базы предлагают свои собственные виды поддержки на низовом уровне. Это не будет похоже на то, что вы получаете от продавца - вы не получите круглосуточную поддержку или ответы на вопросы без проведения внутреннего исследования - но цена ниже.
Итак, большой вопрос - когда стоит покупать инструмент аннотации данных:
Как и в случае со многими видами высокотехнологичных проектов, этот тип анализа - когда строить, а когда покупать - требует целенаправленного обдумывания и рассмотрения того, как эти проекты подбираются и управляются. Проблемы, с которыми сталкивается большинство компаний, связанных с проектами AI / ML при рассмотрении варианта «сборки», связаны не только с частями проекта, связанными с построением и разработкой. Часто требуется огромная кривая обучения, чтобы даже добраться до точки, где может произойти настоящая разработка AI / ML. С новыми командами и инициативами AI / ML количество «неизвестных неизвестных» намного превышает количество «известных неизвестных».
| строить | Покупка |
|---|---|
Плюсы:
| Плюсы:
|
Минусы:
| Минусы:
|
Чтобы упростить задачу, учтите следующие аспекты:
- когда вы работаете с большими объемами данных
- когда вы работаете с разнообразными данными
- когда функции, связанные с вашими моделями или решениями, могут измениться или развиваться в будущем
- когда у вас есть расплывчатый или общий вариант использования
- когда вам нужно четкое представление о расходах, связанных с развертыванием инструмента аннотации данных
- и когда у вас нет подходящей рабочей силы или квалифицированных экспертов для работы с инструментами и вы ищете минимальную кривую обучения
Если ваши ответы были противоположны этим сценариям, вам следует сосредоточиться на создании своего инструмента.
Как правильно выбрать инструмент аннотирования данных для вашего проекта
Если вы читаете это, эти идеи кажутся захватывающими, и их определенно легче сказать, чем сделать. Так как же использовать множество уже существующих инструментов для аннотации данных? Итак, следующий шаг - рассмотрение факторов, связанных с выбором правильного инструмента аннотации данных.
В отличие от нескольких лет назад, сегодня на рынке появилось множество инструментов для аннотации данных. У компаний есть больше вариантов выбора, исходя из своих конкретных потребностей. Но у каждого инструмента есть свои плюсы и минусы. Чтобы принять мудрое решение, помимо субъективных требований необходимо выбрать объективный маршрут.
Давайте посмотрим на некоторые важные факторы, которые вам следует учитывать в процессе.
Определение вашего варианта использования
Чтобы выбрать правильный инструмент аннотации данных, вам необходимо определить свой вариант использования. Вы должны понимать, включает ли ваше требование текст, изображение, видео, аудио или смесь всех типов данных. Есть автономные инструменты, которые вы можете купить, и есть целостные инструменты, которые позволяют выполнять различные действия с наборами данных.
Сегодняшние инструменты интуитивно понятны и предлагают варианты с точки зрения средств хранения (сетевые, локальные или облачные), методов аннотации (аудио, изображения, 3D и др.) И множества других аспектов. Вы можете выбрать инструмент в зависимости от ваших конкретных требований.
Установление стандартов контроля качества
 Это важный фактор, который следует учитывать, поскольку цель и эффективность ваших моделей искусственного интеллекта зависят от установленных вами стандартов качества. Как и при аудите, вам необходимо выполнять проверки качества данных, которые вы вводите, и полученных результатов, чтобы понять, правильно ли обучаются ваши модели и для правильных целей. Однако вопрос в том, как вы собираетесь устанавливать стандарты качества?
Это важный фактор, который следует учитывать, поскольку цель и эффективность ваших моделей искусственного интеллекта зависят от установленных вами стандартов качества. Как и при аудите, вам необходимо выполнять проверки качества данных, которые вы вводите, и полученных результатов, чтобы понять, правильно ли обучаются ваши модели и для правильных целей. Однако вопрос в том, как вы собираетесь устанавливать стандарты качества?
Как и во многих других видах работ, многие люди могут выполнять аннотацию данных и теги, но они делают это с разной степенью успеха. Когда вы запрашиваете услугу, вы не проверяете автоматически уровень контроля качества. Вот почему результаты различаются.
Итак, вы хотите развернуть модель консенсуса, в которой аннотаторы предлагают отзывы о качестве, а корректирующие меры принимаются мгновенно? Или вы предпочитаете выборочную проверку, золотые стандарты или пересечение моделям профсоюзов?
Оптимальный план закупок обеспечит контроль качества с самого начала, установив стандарты до согласования окончательного контракта. Устанавливая это, вы также не должны упускать из виду пределы ошибок. Невозможно полностью избежать ручного вмешательства, поскольку системы неизбежно будут выдавать ошибки с частотой до 3%. Это требует предварительной работы, но оно того стоит.
Кто будет комментировать ваши данные?
Следующий важный фактор зависит от того, кто аннотирует ваши данные. Вы намереваетесь иметь собственную команду или предпочитаете отдать ее на аутсорсинг? Если вы выполняете аутсорсинг, вам необходимо принять во внимание юридические аспекты и меры по соблюдению нормативных требований из-за проблем, связанных с конфиденциальностью и конфиденциальностью данных. А если у вас есть собственная команда, насколько эффективно они изучают новый инструмент? Каково ваше время вывода продукта или услуги на рынок? Есть ли у вас подходящие показатели качества и команды для утверждения результатов?
Продавец против. Партнерские дебаты
 Аннотации данных - это совместный процесс. Это связано с зависимостями и сложностями, такими как совместимость. Это означает, что определенные команды всегда работают в тандеме друг с другом, и одна из команд может быть вашим поставщиком. Вот почему выбранный вами поставщик или партнер так же важен, как и инструмент, который вы используете для маркировки данных.
Аннотации данных - это совместный процесс. Это связано с зависимостями и сложностями, такими как совместимость. Это означает, что определенные команды всегда работают в тандеме друг с другом, и одна из команд может быть вашим поставщиком. Вот почему выбранный вами поставщик или партнер так же важен, как и инструмент, который вы используете для маркировки данных.
С учетом этого фактора, прежде чем пожать руку поставщику или партнеру, следует учитывать такие аспекты, как способность сохранять конфиденциальность ваших данных и намерений, намерение принимать отзывы и работать над ними, проактивность в отношении запросов данных, гибкость в операциях и многое другое. . Мы включили гибкость, потому что требования к аннотации данных не всегда линейны или статичны. Они могут измениться в будущем по мере дальнейшего расширения вашего бизнеса. Если в настоящее время вы имеете дело только с текстовыми данными, возможно, вы захотите аннотировать аудио- или видеоданные по мере масштабирования, и ваша служба поддержки должна быть готова расширить свои горизонты вместе с вами.
Вовлеченность поставщиков
Один из способов оценить участие поставщика - это поддержка, которую вы получите.
Любой план покупки должен учитывать этот компонент. Как будет выглядеть опора на земле? Кто будет заинтересованными сторонами и указателями по обе стороны уравнения?
Существуют также конкретные задачи, в которых необходимо разъяснить, в чем заключается участие поставщика (или будет). В частности, для проекта аннотации данных или маркировки данных будет ли поставщик активно предоставлять необработанные данные или нет? Кто будет выступать в качестве профильных экспертов и кто будет нанимать их в качестве сотрудников или независимых подрядчиков?
Сферы деятельности
Вот несколько конкретных примеров из практики, которые показывают, как аннотации и маркировка данных действительно работают на местах. В Shaip мы заботимся о том, чтобы обеспечить высочайший уровень качества и превосходные результаты при аннотации и маркировке данных.
Большая часть приведенного выше обсуждения стандартных достижений в области аннотации и маркировки данных показывает, как мы подходим к каждому проекту и что мы предлагаем компаниям и заинтересованным сторонам, с которыми мы работаем.
Материалы тематического исследования, которые продемонстрируют, как это работает:

В рамках проекта лицензирования клинических данных команда Shaip обработала более 6,000 часов аудио, удалив всю защищенную медицинскую информацию (PHI) и оставив HIPAA-совместимый контент для медицинских моделей распознавания речи.
В этом случае важны критерии и классификация достижений. Необработанные данные представлены в виде звука, поэтому необходимо деидентифицировать стороны. Например, при использовании анализа NER двойная цель состоит в том, чтобы деидентифицировать и аннотировать контент.
Другое тематическое исследование включает в себя подробное разговорные данные обучения ИИ проект, который мы завершили с 3,000 лингвистов, работающих в течение 14 недель. Это привело к созданию обучающих данных на 27 языках с целью развития многоязычных цифровых помощников, способных обрабатывать человеческие взаимодействия на широком выборе родных языков.
В этом конкретном случае очевидна необходимость посадить нужного человека на нужный стул. Большое количество экспертов в предметной области и операторов ввода контента означало, что существовала необходимость в организационной и процедурной оптимизации, чтобы проект был выполнен в определенные сроки. Наша команда смогла с большим отрывом превзойти отраслевые стандарты за счет оптимизации сбора данных и последующих процессов.
Другие типы тематических исследований включают такие вещи, как обучение ботов и текстовые аннотации для машинного обучения. Опять же, в текстовом формате по-прежнему важно обрабатывать идентифицированные стороны в соответствии с законами о конфиденциальности и сортировать необработанные данные для получения целевых результатов.
Другими словами, работая с несколькими типами и форматами данных, Shaip продемонстрировал одинаковый жизненно важный успех, применив одни и те же методы и принципы как к необработанным данным, так и к бизнес-сценариям лицензирования данных.