


Что такое разговорный ИИ
Разговорный ИИ — это усовершенствованная форма искусственного интеллекта, которая позволяет машинам участвовать в интерактивных диалогах, подобных человеческим, с пользователями. Эта технология понимает и интерпретирует человеческий язык для имитации естественного разговора. Он может учиться на взаимодействиях с течением времени, чтобы реагировать контекстуально.
Разговорные системы ИИ широко используются в таких приложениях, как чат-боты, голосовые помощники и платформы поддержки клиентов по цифровым и телекоммуникационным каналам.
В последние годы рынок разговорного ИИ переживает стремительный рост. Первоначально разработанный для развлекательных целей, разговорный ИИ стал неотъемлемой частью цифровой экосистемы. Вот некоторые ключевые статистические данные, иллюстрирующие его влияние:
- Мировой рынок диалогового ИИ оценивался в 6.8 млрд долларов в 2021 году и, по прогнозам, вырастет до 18.4 млрд долларов к 2026 году при среднегодовом темпе роста 22.6%. Ожидается, что к 2028 году объем рынка достигнет 29.8 млрд долларов США .
- Несмотря на свою распространенность, 63% пользователей не подозревают, что используют ИИ в своей повседневной жизни.
- A Опрос Gartner обнаружили, что многие компании определили чат-ботов в качестве своего основного приложения ИИ, и ожидается, что к 70 году почти 2022% белых воротничков будут ежедневно взаимодействовать с диалоговыми платформами.
- После пандемии объем взаимодействий, осуществляемых диалоговыми агентами, увеличился на 250% по нескольким отраслям.
- Доля маркетологов, использующих ИИ для цифрового маркетинга во всем мире, резко выросла с 29% в 2018 году до 84% в 2020.
- В 2022, 91% взрослых пользователей голосового помощника использовали технологию разговорного ИИ на своих смартфонах.
- Просмотр и поиск продуктов были лучшие торговые мероприятия проведенный с использованием технологии голосового помощника среди пользователей в США в ходе опроса 2021 года.
- Среди технических специалистов во всем мире почти 80% использовать виртуальных помощников для обслуживания клиентов.
- К 2024 году 73% лиц, ответственных за обслуживание клиентов в Северной Америке, считают, что онлайн-чат, видеочат, чат-боты или социальные сети станут наиболее используемые каналы обслуживания клиентов.
- В опросе 2021 г. 86% руководителей США согласились с тем, что искусственный интеллект станет «основной технологией» в их компании.
- По состоянию на февраль 2022 года 53% взрослых американцев за последний год общались с чат-ботом с искусственным интеллектом для обслуживания клиентов.
- В 2022, 3.5 млрд штук. приложения чат-ботов были доступны по всему миру.
- Ассоциация три основные причины Американские потребители используют чат-бота в рабочее время (18%), информацию о продукте (17%) и запросы на обслуживание клиентов (16%).
Эти статистические данные свидетельствуют о растущем внедрении и влиянии диалогового ИИ в различных отраслях и на поведение потребителей.
Как работает разговорный ИИ
Разговорный ИИ использует обработку естественного языка (NLP) и другие сложные алгоритмы для участия в диалогах с богатым контекстом. По мере того, как ИИ сталкивается с более широким диапазоном пользовательских входных данных, он улучшает свои способности распознавания образов и прогнозирования. Процесс диалогового взаимодействия ИИ с пользователями можно разбить на четыре ключевых этапа:

Шаг 1: Сбор входных данных – Пользователи вводят данные либо текстом, либо голосом.
Шаг 2: Обработка ввода – Когда ввод осуществляется в текстовой форме, для извлечения смысла из слов используется понимание естественного языка (NLU). Для голосового ввода сначала используется автоматическое распознавание речи (ASR) для преобразования звука в языковые маркеры, которые можно дополнительно анализировать.
Шаг 3: Генерация ответа – Методы генерации естественного языка используются для надлежащего ответа на запрос пользователя.
Шаг 4: Постоянное совершенствование – Разговорные системы искусственного интеллекта анализируют вводимые пользователем данные с течением времени, уточняя их ответы для обеспечения точности и актуальности.

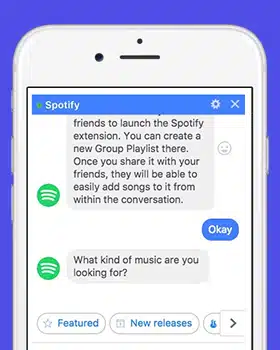
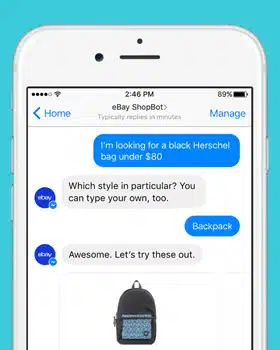

Устранение общих проблем с данными в диалоговом ИИ
Разговорный ИИ динамически преобразует общение человека с компьютером. И многие компании заинтересованы в разработке передовых инструментов и приложений для разговорного ИИ, которые могут изменить способ ведения бизнеса. Однако, прежде чем разрабатывать чат-бота, который может улучшить общение между вами и вашими клиентами, вы должны рассмотреть множество ловушек при разработке, с которыми вы можете столкнуться.
Языковое разнообразие
 Разработка помощника по чату, который может поддерживать несколько языков, является сложной задачей. Кроме того, огромное разнообразие мировых языков затрудняет разработку чат-бота, который беспрепятственно обеспечивает обслуживание всех клиентов.
Разработка помощника по чату, который может поддерживать несколько языков, является сложной задачей. Кроме того, огромное разнообразие мировых языков затрудняет разработку чат-бота, который беспрепятственно обеспечивает обслуживание всех клиентов.
В 2022, около 1.5 миллиарда человек говорили по-английски во всем мире, за ним следует китайский мандарин с 1.1 миллиарда говорящих. Хотя английский язык является наиболее распространенным и изучаемым иностранным языком в мире, только около 20% населения мира говорит на нем. Это заставляет остальную часть населения мира — 80% — говорить на языках, отличных от английского. Таким образом, при разработке чат-бота вы также должны учитывать языковое разнообразие.
Языковая изменчивость
Люди говорят на разных языках и на одном и том же языке по-разному. К сожалению, машина все еще не может полностью понять вариативность разговорного языка, учитывая эмоции, диалекты, произношение, акценты и нюансы.
Наши слова и выбор языка также отражаются на том, как мы печатаем. Можно ожидать, что машина поймет и оценит изменчивость языка только тогда, когда группа аннотаторов обучит ее различным наборам речевых данных.
Динамизм в речи
Еще одна серьезная проблема при разработке разговорного ИИ — привнести в бой динамизм речи. Например, в разговоре мы используем несколько наполнителей, пауз, фрагментов предложений и неразборчивых звуков. Кроме того, речь намного сложнее, чем письменное слово, поскольку мы обычно не делаем паузы между каждым словом и ударением на правильном слоге.
Когда мы слушаем других, мы склонны определять намерение и смысл их разговора, используя свой жизненный опыт. В результате мы контекстуализируем и понимаем их слова, даже если они двусмысленны. Однако машина не способна на это качество.
Зашумленные данные
Шумные данные или фоновый шум — это данные, которые не представляют ценности для разговоров, например дверные звонки, собаки, дети и другие фоновые звуки. Поэтому важно очищать или фильтровать аудиофайлы этих звуков и обучить систему ИИ распознавать важные и второстепенные звуки.
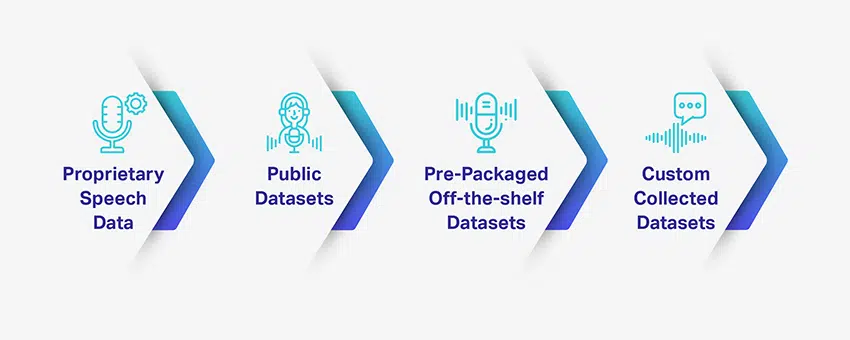
Плюсы и минусы разных типов речевых данных
 Создание системы распознавания голоса на базе ИИ или разговорного ИИ требует множества обучающих и тестовых наборов данных. Однако получить доступ к таким качественным наборам данных — надежным и отвечающим потребностям вашего конкретного проекта — непросто. Тем не менее, есть варианты, доступные для компаний, которые ищут наборы данных для обучения, и каждый вариант имеет свои преимущества и недостатки.
Создание системы распознавания голоса на базе ИИ или разговорного ИИ требует множества обучающих и тестовых наборов данных. Однако получить доступ к таким качественным наборам данных — надежным и отвечающим потребностям вашего конкретного проекта — непросто. Тем не менее, есть варианты, доступные для компаний, которые ищут наборы данных для обучения, и каждый вариант имеет свои преимущества и недостатки.
Если вы ищете общий тип набора данных, у вас есть множество вариантов публичного выступления. Однако для чего-то более конкретного и соответствующего требованиям вашего проекта вам, возможно, придется собирать и настраивать его самостоятельно.
Собственные речевые данные
В первую очередь нужно искать собственные данные вашей компании. Однако, поскольку у вас есть законное право и согласие на использование речевых данных ваших клиентов, вы можете использовать этот массивный набор данных для обучения и тестирования своих проектов.
Плюсы:
- Никаких дополнительных затрат на сбор данных для обучения
- Данные обучения, вероятно, имеют отношение к вашему бизнесу.
- Речевые данные также имеют естественную фоновую акустику окружающей среды, динамических пользователей и устройства.
Минусы:
- Использование таких данных может стоить вам кучу денег за разрешение на запись и использование.
- Речевые данные могут иметь языковые, демографические или клиентские ограничения.
- Данные могут быть бесплатными, но вы все равно будете платить за обработку, расшифровку, тегирование и многое другое.
Общедоступные наборы данных
Наборы данных публичной речи — еще один вариант, если вы не собираетесь использовать свой. Эти наборы данных являются частью общественного достояния и могут быть собраны для проектов с открытым исходным кодом.
Плюсы:
- Общедоступные наборы данных бесплатны и идеально подходят для малобюджетных проектов.
- Они доступны для немедленной загрузки
- Общедоступные наборы данных представлены в виде различных наборов образцов со сценариями и без них.
Минусы:
- Затраты на обработку и обеспечение качества могут быть высокими
- Качество наборов данных публичной речи различается в значительной степени.
- Предлагаемые образцы речи обычно носят общий характер, что делает их непригодными для разработки конкретных речевых проектов.
- Наборы данных обычно смещены в сторону английского языка.
Предварительно упакованные/готовые наборы данных
Изучение предварительно упакованных наборов данных — еще один вариант, если общедоступные данные или проприетарные сбор речевых данных не соответствует вашим потребностям.
Поставщик собрал предварительно упакованные наборы речевых данных для конкретной цели перепродажи клиентам. Этот тип набора данных можно использовать для разработки общих приложений или конкретных целей.
Плюсы:
- Вы можете получить доступ к набору данных, который соответствует вашим конкретным потребностям в речевых данных.
- Использование готовых наборов данных более доступно, чем сбор собственных.
- Возможно, вы сможете быстро получить доступ к набору данных.
Минусы:
- Поскольку набор данных предварительно упакован, он не настраивается под нужды вашего проекта.
- Более того, набор данных не уникален для вашей компании, поскольку его может приобрести любой другой бизнес.
Выберите пользовательские наборы собранных данных
При создании речевого приложения вам потребуется обучающий набор данных, отвечающий всем вашим конкретным требованиям. Однако крайне маловероятно, что вы получите доступ к предварительно упакованному набору данных, отвечающему уникальным требованиям вашего проекта. Единственный доступный вариант — создать собственный набор данных или приобрести его у сторонних поставщиков решений.
Наборы данных для обучения и тестирования полностью настраиваются. Вы можете включить динамизм языка, разнообразие речевых данных и доступ к различным участникам. Кроме того, набор данных можно масштабировать для своевременного удовлетворения потребностей вашего проекта.
Плюсы:
- Наборы данных собираются для вашего конкретного варианта использования. Вероятность того, что алгоритмы ИИ отклонятся от намеченных результатов, сведена к минимуму.
- Контролируйте и уменьшайте предвзятость в данных ИИ
Минусы:
- Наборы данных могут быть дорогостоящими и занимать много времени; однако выгоды всегда перевешивают затраты.

Отрасли, использующие диалоговый ИИ
В настоящее время разговорный ИИ преимущественно используется в качестве чат-ботов. Тем не менее, несколько отраслей внедряют эту технологию, чтобы получить огромные преимущества. Некоторые из отраслей, использующих разговорный ИИ:
Здоровье
 Разговорный ИИ оказывает огромное влияние на сектор здравоохранения. Диалоговый ИИ оказался полезным для пациентов, врачей, персонала, медсестер и другого медицинского персонала.
Разговорный ИИ оказывает огромное влияние на сектор здравоохранения. Диалоговый ИИ оказался полезным для пациентов, врачей, персонала, медсестер и другого медицинского персонала.
Некоторые из преимуществ
- Взаимодействие с пациентом на этапе после лечения
- Чат-боты для планирования встреч
- Отвечаем на часто задаваемые вопросы и общие вопросы
- Оценка симптомов
- Выявление пациентов в критическом состоянии
- Эскалация экстренных случаев
E-commerce
 Диалоговый ИИ помогает предприятиям электронной коммерции взаимодействовать со своими клиентами, предоставлять индивидуальные рекомендации и продавать продукты.
Диалоговый ИИ помогает предприятиям электронной коммерции взаимодействовать со своими клиентами, предоставлять индивидуальные рекомендации и продавать продукты.
Индустрия электронной коммерции максимально использует преимущества этой лучшей в своем классе технологии.
- Сбор информации о клиентах
- Предоставлять актуальную информацию о продукте и рекомендации
- Улучшение удовлетворенности клиентов
- Помощь в оформлении заказов и возвратов
- Ответить на часто задаваемые вопросы
- Кросс-продажи и допродажи продуктов
Банковское дело
 Банковский сектор внедряет диалоговые инструменты искусственного интеллекта для улучшения взаимодействия с клиентами, обработки запросов в режиме реального времени и обеспечения упрощенного и унифицированного обслуживания клиентов по нескольким каналам.
Банковский сектор внедряет диалоговые инструменты искусственного интеллекта для улучшения взаимодействия с клиентами, обработки запросов в режиме реального времени и обеспечения упрощенного и унифицированного обслуживания клиентов по нескольким каналам.
- Разрешить клиентам проверять свой баланс в режиме реального времени
- Помощь с депозитами
- Помощь в подаче налоговой декларации и получении кредита
- Оптимизируйте банковский процесс, отправляя напоминания о счетах, уведомления и оповещения.
Страхование
 Подобно банковскому сектору, страховая отрасль также пользуется цифровыми технологиями разговорного ИИ и пожинает его плоды. Например, диалоговый ИИ помогает страховой отрасли предоставлять более быстрые и надежные средства разрешения конфликтов и претензий.
Подобно банковскому сектору, страховая отрасль также пользуется цифровыми технологиями разговорного ИИ и пожинает его плоды. Например, диалоговый ИИ помогает страховой отрасли предоставлять более быстрые и надежные средства разрешения конфликтов и претензий.
- Предоставление рекомендаций по политике
- Более быстрое урегулирование претензий
- Устранение времени ожидания
- Собирайте отзывы и отзывы от клиентов
- Повышение осведомленности клиентов о политиках
- Управляйте более быстрыми заявками и продлением

Шайп Предложение
Когда дело доходит до предоставления качественных и надежных наборов данных для разработки передовых речевых приложений для взаимодействия человека и машины, Shaip лидирует на рынке благодаря успешному развертыванию. Однако в условиях острой нехватки чат-ботов и речевых помощников компании все чаще обращаются к услугам Shaip — лидера рынка — для предоставления индивидуальных, точных и качественных наборов данных для обучения и тестирования проектов ИИ.
Комбинируя обработку естественного языка, мы можем обеспечить персонализированный опыт, помогая разрабатывать точные речевые приложения, которые эффективно имитируют человеческие разговоры. Мы используем множество передовых технологий для обеспечения высокого качества обслуживания клиентов. НЛП учит машины интерпретировать человеческие языки и взаимодействовать с людьми.
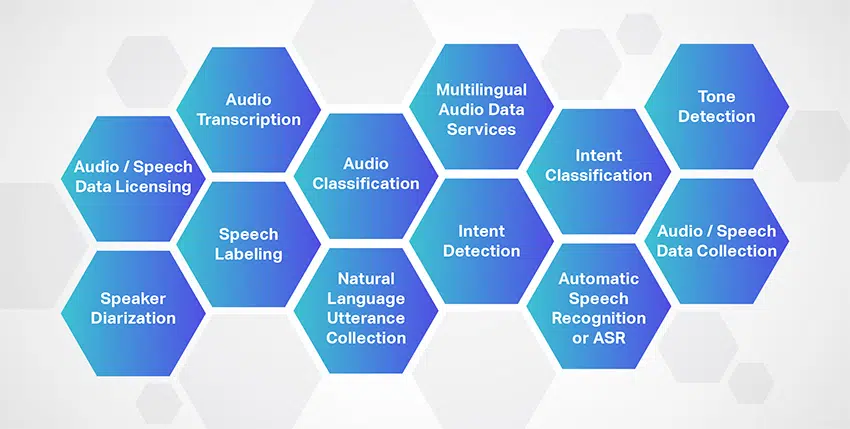
Аудио транскрипция
Shaip — ведущий поставщик услуг транскрипции аудио, предлагающий широкий выбор речевых и аудиофайлов для всех типов проектов. Кроме того, Shaip предлагает услугу транскрипции, на 100% созданную человеком, для преобразования аудио- и видеофайлов — интервью, семинаров, лекций, подкастов и т. д. в легко читаемый текст.
Речевая маркировка
Shaip предлагает обширные услуги по маркировке речи, умело разделяя звуки и речь в аудиофайле и маркируя каждый файл. Точно разделяя похожие звуковые звуки и комментируя их,
Диаризация спикера
Опыт Sharp распространяется на предложение превосходных решений для диаризации динамиков путем сегментации аудиозаписи на основе их источника. Кроме того, границы громкоговорителей точно идентифицируются и классифицируются, например, громкоговоритель 1, громкоговоритель 2, музыка, фоновый шум, автомобильные звуки, тишина и т. д., для определения количества громкоговорителей.
Классификация аудио
Аннотирование начинается с классификации аудиофайлов по заранее определенным категориям. Категории зависят главным образом от требований проекта и обычно включают в себя намерения пользователя, язык, семантическую сегментацию, фоновый шум, общее количество говорящих и многое другое.
Коллекция высказываний на естественном языке / слова для пробуждения
Трудно предсказать, что клиент всегда будет выбирать похожие слова, задавая вопрос или инициируя запрос. Например, «Где ближайший ресторан?» «Найти рестораны рядом со мной» или «Есть ли поблизости ресторан?»
Все три высказывания имеют одно и то же намерение, но формулируются по-разному. Путем перестановок и комбинаций опытные специалисты по разговорному искусственному интеллекту в Shaip определят все возможные комбинации, возможные для формулировки одного и того же запроса. Shaip собирает и аннотирует высказывания и слова пробуждения, уделяя особое внимание семантике, контексту, тону, дикции, времени, ударению и диалектам.
Многоязычные службы аудиоданных
Многоязычные услуги аудиоданных — еще одно очень предпочтительное предложение от Shaip, поскольку у нас есть команда сборщиков данных, собирающих аудиоданные на более чем 150 языках и диалектах по всему миру.
Обнаружение намерений
Человеческие взаимодействия и общение часто более сложны, чем мы думаем. И это врожденное усложнение затрудняет обучение модели машинного обучения точному пониманию человеческой речи.
Более того, разные люди из одной и той же демографической группы или из разных демографических групп могут по-разному выражать одни и те же намерения или чувства. Таким образом, система распознавания речи должна быть обучена распознавать общие намерения независимо от демографических данных.
Чтобы вы могли обучить и разработать первоклассную модель машинного обучения, наши логопеды предоставляют обширные и разнообразные наборы данных, чтобы помочь системе идентифицировать несколько способов, которыми люди выражают одно и то же намерение.
Классификация намерений
Подобно тому, как выявляются одинаковые намерения разных людей, ваши чат-боты также должны быть обучены классифицировать комментарии клиентов по различным категориям, заранее определенным вами. Каждый чат-бот или виртуальный помощник спроектирован и разработан с определенной целью. Shaip может классифицировать намерения пользователя по предопределенным категориям по мере необходимости.
Автоматическое распознавание речи или ASR
Распознавание речи» относится к преобразованию произносимых слов в текст; однако распознавание голоса и идентификация говорящего направлены на идентификацию как разговорного контента, так и личности говорящего. Точность ASR определяется различными параметрами, т. е. громкостью динамика, фоновым шумом, записывающим оборудованием и т. д.
Обнаружение тона
Еще одним интересным аспектом человеческого взаимодействия является тон: мы внутренне распознаем значение слов в зависимости от тона, с которым они произносятся. Хотя то, что мы говорим, важно, то, как мы произносим эти слова, также передает смысл.
Например, такая простая фраза, как «Какая радость!» может быть восклицанием счастья, а также может быть саркастическим. Это зависит от тона и напряжения.
'Что ты делаешь?'
'Что ты делаешь?'
В обоих этих предложениях есть точные слова, но ударение в словах разное, что меняет весь смысл предложений. Чат-бот обучен распознавать радость, сарказм, гнев, раздражение и другие выражения. Именно здесь в игру вступает опыт логопедов и аннотаторов Sharp.
Лицензирование аудио/речевых данных
Shaip предлагает наборы речевых данных непревзойденного качества, которые можно настроить в соответствии с конкретными потребностями вашего проекта. Большинство наших наборов данных могут вписаться в любой бюджет, а данные можно масштабировать для удовлетворения всех будущих потребностей проекта. Мы предлагаем более 40 100 часов готовых наборов речевых данных на более чем 50 диалектах на более чем XNUMX языках. Мы также предоставляем ряд типов аудио, в том числе спонтанные, монолог, сценарий и слова пробуждения. Посмотреть весь Каталог данных.
Сбор аудио/речевых данных
При нехватке качественных наборов речевых данных итоговое речевое решение может быть пронизано проблемами и ненадежным. Shaip — один из немногих провайдеров, которые предоставляют многоязычные аудиоколлекции, транскрипцию аудио и инструменты аннотации и сервисы, которые полностью настраиваются под проект.
Речевые данные можно рассматривать как спектр, идущий от естественной речи на одном конце до неестественной речи на другом. В естественной речи говорящий говорит в спонтанной разговорной манере. С другой стороны, неестественные звуки речи ограничены, когда говорящий читает сценарий. Наконец, говорящим предлагается произнести слова или фразы в контролируемой манере в середине спектра.
Опыт Sharp распространяется на предоставление различных типов наборов речевых данных на более чем 150 языках.

































случай
Мы работали с некоторыми ведущими компаниями и брендами и предоставили им решения для разговорного ИИ самого высокого уровня.
Некоторые из наших историй успеха включают:
- Мы разработали набор данных распознавания речи с более чем 10,000 XNUMX часов многоязычных транскрипций, разговоров и аудиофайлов для обучения и создания живого чат-бота.
- Мы создали высококачественный набор данных из 1000 разговоров по 6 оборотов на разговор, используемый для обучения страхового чат-бота.
- Наша команда из более чем 3000 лингвистов предоставила более 1000 часов аудиофайлов и стенограмм на 27 родных языках для обучения и тестирования цифрового помощника.
- Наша команда аннотаторов и лингвистов также быстро собрала и доставила более 20,000 27 часов высказываний на более чем XNUMX языках мира.
- Наши услуги автоматического распознавания речи являются одними из самых популярных в отрасли. Мы предоставили аудиофайлы с надежной маркировкой, уделив особое внимание произношению, тону и намерению, используя широкий спектр транскрипций и лексики из различных наборов динамиков, чтобы повысить надежность моделей ASR.
Наши истории успеха проистекают из стремления нашей команды всегда предоставлять лучшие услуги с использованием новейших технологий для наших клиентов. Что отличает нас от других, так это то, что наша работа поддерживается экспертами-аннотаторами, которые предоставляют беспристрастные и точные наборы данных аннотаций золотого стандарта.
Наша команда по сбору данных, состоящая из более чем 30,000 участников, может получать, масштабировать и предоставлять высококачественные наборы данных, которые помогают быстро развертывать модели машинного обучения. Кроме того, мы работаем на новейшей платформе на основе искусственного интеллекта и можем предоставлять предприятиям решения для ускоренной обработки речевых данных намного быстрее, чем наши ближайшие конкуренты.
