
Модели больших языков недавно приобрели огромную известность после того, как их высококвалифицированный вариант использования ChatGPT стал в одночасье успешным. Увидев успех ChatGPT и других чат-ботов, множество людей и организаций заинтересовались изучением технологии, лежащей в основе такого программного обеспечения.
Модели большого языка являются основой этого программного обеспечения, которое позволяет работать с различными приложениями обработки естественного языка, такими как машинный перевод, распознавание речи, ответы на вопросы и суммирование текста. Давайте узнаем больше о LLM и о том, как вы можете оптимизировать его для достижения наилучших результатов.
Что такое большие языковые модели или ChatGPT?
Большие языковые модели — это модель машинного обучения, которая использует искусственные нейронные сети и большие хранилища данных для поддержки приложений НЛП. После обучения на больших объемах данных LLM получает возможность фиксировать различные сложности естественного языка, которые он в дальнейшем использует для:
- Генерация нового текста
- Обобщение статей и отрывков
- Извлечение данных
- Переписать или перефразировать текст
- Классификация данных
Некоторыми популярными примерами LLM являются BERT, Chat GPT-3 и XLNet. Эти модели обучаются на сотнях миллионов текстов и могут предоставить полезные решения для всех типов различных пользовательских запросов.
Популярные варианты использования больших языковых моделей
Вот некоторые из лучших и наиболее распространенных вариантов использования LLM:
Генерация текста
Модели больших языков используют искусственный интеллект и знания компьютерной лингвистики для автоматического создания текстов на естественном языке и выполнения различных коммуникативных пользовательских требований, таких как написание статей, песен или даже общение с пользователями.
Машинный перевод
LLM также можно использовать для перевода текста между любыми двумя языками. В моделях используются алгоритмы глубокого обучения, такие как рекуррентные нейронные сети, для изучения языковой структуры исходного и целевого языков. Соответственно, они используются для перевода исходного текста на целевой язык.
Content Creation
LLM теперь позволили машинам создавать связный и логичный контент, который можно использовать для создания сообщений в блогах, статей и других форм контента. Модели используют свои обширные знания глубокого обучения, чтобы понять и структурировать контент в уникальном и удобном для пользователей формате.
Анализ настроений
Это захватывающий вариант использования больших языковых моделей, в котором модель обучена идентифицировать и классифицировать эмоциональные состояния и чувства в помеченном тексте. Программное обеспечение может обнаруживать такие эмоции, как позитивность, негативность, нейтральность и другие сложные чувства, которые могут помочь получить представление о мнениях и отзывах клиентов о различных продуктах и услугах.
Понимание, обобщение и классификация текста
LLM обеспечивают практическую основу для программного обеспечения ИИ для понимания текста и его контекста. Обучая модель понимать и анализировать большие объемы данных, LLM позволяет моделям ИИ понимать, обобщать и даже классифицировать текст в различных формах и шаблонах.
Ответ на вопрос
Модели большого языка позволяют системам контроля качества точно обнаруживать запросы пользователя на естественном языке и отвечать на них. Одними из самых популярных приложений этого варианта использования являются ChatGPT и BERT, которые анализируют контекст запроса и выполняют поиск по большому массиву текстов, чтобы найти релевантные ответы на запросы пользователей.
[Также читайте: Будущее языковой обработки: большие языковые модели и примеры ]

3 основных условия успеха LLM
Следующие три условия должны быть точно выполнены, чтобы повысить эффективность и сделать ваши модели больших языков успешными:
Наличие огромного количества данных для обучения модели
LLM требуются большие объемы данных для обучения моделей, обеспечивающих эффективные и оптимальные результаты. Существуют специальные методы, такие как трансферное обучение и предварительное обучение с самоконтролем, которые LLM используют для повышения своей производительности и точности.
Построение слоев нейронов для облегчения сложных паттернов в моделях
Большая языковая модель должна состоять из различных слоев нейронов, специально обученных для понимания сложных закономерностей в данных. Нейроны в более глубоких слоях могут лучше понимать сложные паттерны, чем более мелкие слои. Модель может изучать ассоциации между словами, темы, которые появляются вместе, и отношения между частями речи.
Оптимизация LLM для пользовательских задач
LLM можно настроить для конкретных задач, изменив количество слоев, нейронов и функций активации. Например, модель, которая предсказывает следующее слово в предложении, обычно использует меньше слоев и нейронов, чем модель, предназначенная для создания новых предложений с нуля.
Популярные примеры больших языковых моделей
Вот несколько ярких примеров LLM, широко используемых в различных отраслевых вертикалях:
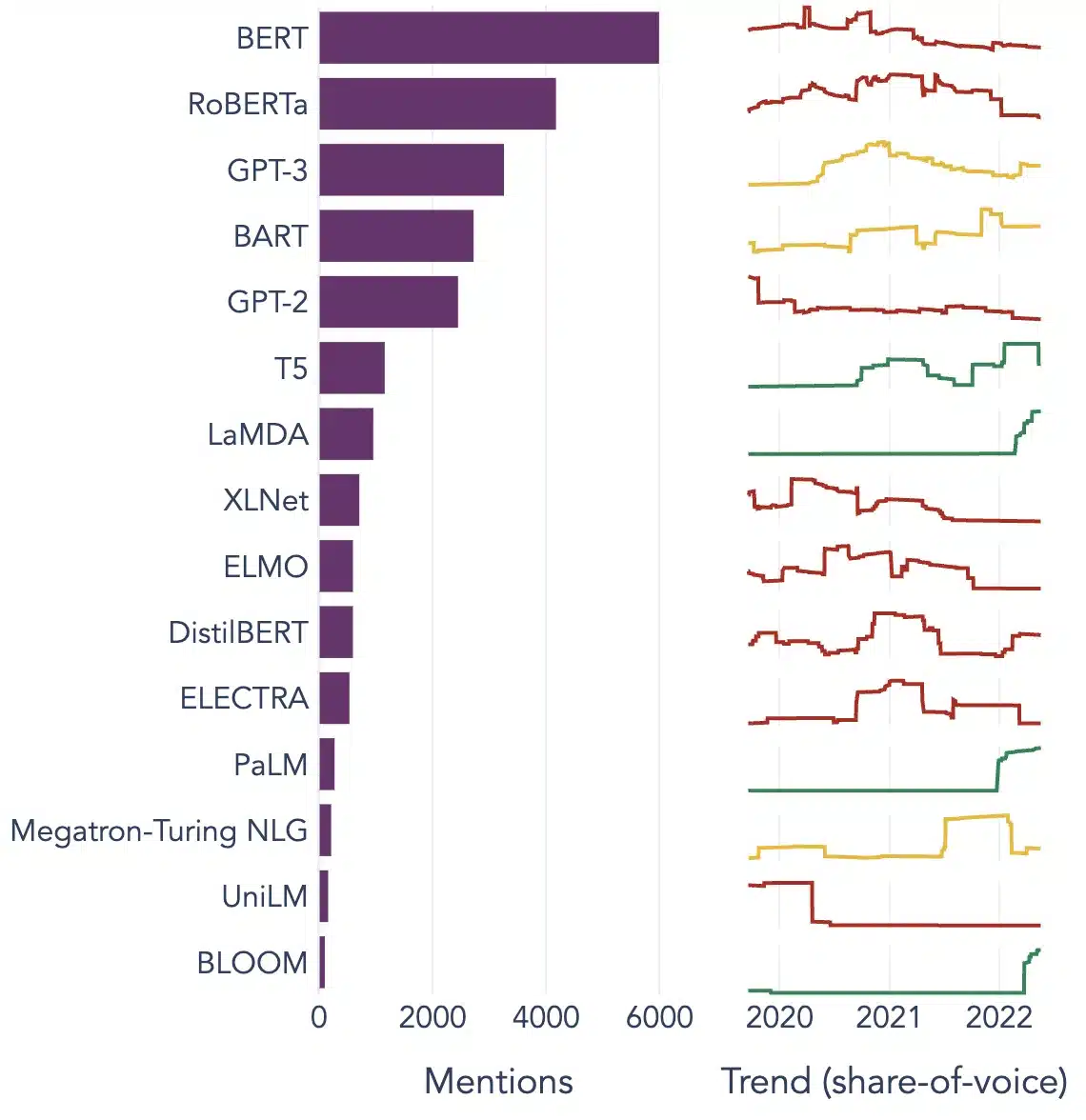
Image Source: На пути к науке о данных
Заключение
LLM видят потенциал революционизировать NLP, предоставляя надежные и точные возможности и решения для понимания языка, которые обеспечивают беспрепятственный пользовательский опыт. Однако, чтобы сделать LLM более эффективными, разработчики должны использовать высококачественные речевые данные для получения более точных результатов и создания высокоэффективных моделей ИИ.
Shaip — одно из ведущих технологических решений в области искусственного интеллекта, которое предлагает широкий спектр речевых данных на более чем 50 языках и в различных форматах. Узнайте больше о LLM и получите рекомендации по своим проектам от Эксперты Shaip сегодня.


