

Качество и точность результатов, предоставляемых системой распознавания лиц и эмоций, зависят от данных. Чем точнее и обширнее данные, тем выше шансы программы ИИ идентифицировать и обнаружить эмоции.

Искусственный интеллект имеет ряд огромных преимуществ для страховой отрасли, при условии, что компании понимают его реализацию. Оптимизация таких задач, как обработка претензий, настройка премий и обнаружение ущерба, также может помочь в обслуживании клиентов, повышая общий уровень удовлетворенности.

Обезличивание данных имеет решающее значение для защиты личной информации в здравоохранении и соответствует нормативным требованиям, таким как HIPAA и GDPR. Представленные инструменты, в том числе IBM InfoSphere Optim, Google Healthcare API, AWS Comprehend Medical, Shaip и Private-AI, предлагают разнообразные решения для эффективного маскировки данных.

Генеративный искусственный интеллект обладает рядом мощных функций и возможностей, предназначенных для модернизации систем поддержки клиентов. Если генеративный ИИ может оперативно решать проблемы клиентов, он также может заменить агентов в качестве служб быстрого реагирования и общаться с клиентами, как человек.

Обезличивание данных — важнейшая процедура обеспечения защиты от несанкционированного доступа и неправомерного использования персональных данных. Этот процесс особенно важен для медицинских данных: он гарантирует, что никакая личная информация не попадет в руки лиц, кроме тех, кто тесно связан с этими данными.

Разговорный и генеративный ИИ меняет наш мир уникальными способами. Разговорный ИИ делает общение с машинами простым и полезным, улучшая поддержку клиентов и медицинские услуги. Генеративный ИИ, с другой стороны, является творческой силой. Он изобретает новый, оригинальный контент в области искусства, музыки и многого другого. Понимание этих типов ИИ является ключом к разумным бизнес-, этическим и инновационным решениям.

Голосовые технологии все еще являются относительно новыми технологиями, и мы все еще работаем над тем, чтобы лучше понять решения, предлагаемые с их помощью. В условиях срочной медицинской помощи эффективность и точность имеют первостепенное значение.

Генеративный ИИ меняет ландшафт банковских и финансовых услуг, повышая эффективность, повышая безопасность и предоставляя персонализированный опыт как для клиентов, так и для учреждений. Поскольку технология продолжает развиваться, ее влияние на финансовую индустрию, вероятно, будет расти, открывая новую эру инноваций и оптимизации.

Использование обработки естественного языка (NLP) в здравоохранении и фармацевтической промышленности в значительной степени основано на анализе неструктурированных данных. Обладая соответствующей информацией, организации здравоохранения могут извлечь ряд преимуществ и предоставить пациентам более качественные медицинские услуги.

Количество и частота пользовательского контента в ближайшие годы будут увеличиваться. Сегодня клиенты имеют доступ к инновационным инструментам, позволяющим им знать все о бренде. Там, где для бренда важно взаимодействие с существующими, новыми и потенциальными клиентами, мониторинг и модерация контента имеют решающее значение для создания положительного имиджа.

Эффективная маркировка данных является важной частью повышения релевантности поиска. Платформы и предприятия электронной коммерции получают наибольшую выгоду от маркировки данных, поскольку им необходимо отображать свои продукты в результатах поиска, что приводит к увеличению продаж и доходов.

Обработка естественного языка (НЛП) положила начало революции в извлечении и анализе информации во всех отраслях. Универсальность этой технологии также развивается, позволяя предлагать лучшие решения и новые приложения. Использование НЛП в финансах не ограничивается упомянутыми выше приложениями. Со временем мы сможем использовать эту технологию и ее методы для еще более сложных задач и операций.

В основе применения ИИ в здравоохранении лежат данные и их правильный анализ. Используя эти данные и информацию, предоставленную медицинскими работниками, инструменты и технологии искусственного интеллекта способны предоставлять более эффективные решения в области здравоохранения с точки зрения диагностики, лечения, прогнозирования, назначения рецептов и визуализации.

Распознавание именованных объектов — жизненно важный метод, открывающий путь к более глубокому машинному пониманию текста. Хотя наборы данных с открытым исходным кодом имеют свои преимущества и недостатки, они играют важную роль в обучении и точной настройке моделей NER. Разумный выбор и применение этих ресурсов могут значительно улучшить результаты проектов НЛП.

Генеративный искусственный интеллект предлагает замечательные преимущества, такие как эффективность, масштабируемость и персонализация, а также способность создавать разнообразный контент. Однако такие проблемы, как контроль качества, ограничения творческих способностей и этические проблемы, требуют пристального внимания.

Генеративный искусственный интеллект — это захватывающий рубеж, который переопределяет границы технологий и творчества. От создания человеческого текста до создания реалистичных изображений, улучшения разработки кода и даже моделирования уникальных аудиовыходов — его реальные приложения столь же разнообразны, сколь и революционны.

Применение машинного обучения и искусственного интеллекта в анализе клинических данных обширно и новаторски. Они открывают огромный потенциал для изменения ухода за пациентами, улучшения медицинских исследований и обеспечения более ранней и точной диагностики.

Shaip находится в авангарде предоставления первоклассных медицинских и медицинских данных, жизненно важных для моделей искусственного интеллекта и машинного обучения (ML). Если вы приступаете к проекту искусственного интеллекта для здравоохранения или вам нужны конкретные медицинские данные, Shaip — идеальный партнер.

Голосовые помощники уже не новинка; они быстро становятся жизненно важными для нашего ежедневного цифрового взаимодействия. Появление многоязычного голосового помощника обещает стать значительным шагом вперед, преодолевая языковые барьеры и способствуя более широкому глобальному взаимодействию.
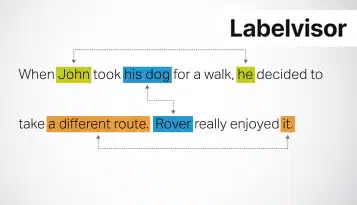
Аннотации документов являются важным строительным блоком в области искусственного интеллекта, машинного обучения и обработки естественного языка. Он расширяет возможности систем искусственного интеллекта для понимания и обработки, обеспечивая эффективное извлечение информации и автоматизацию в различных областях.

Как мы рассмотрели в приведенных выше примерах, анализ настроений обладает замечательным потенциалом в различных приложениях, от обслуживания клиентов до политики. Это позволяет организациям раскрыть потенциал субъективных данных и преобразовать неструктурированный текст в полезную информацию.

Будущее искусственного интеллекта в здравоохранении многообещающее и потенциальное, а новые тенденции на 2023 год сигнализируют о коренном сдвиге в оказании помощи пациентам.

Варианты использования обработки естественного языка в здравоохранении обширны и преобразуют. Используя возможности искусственного интеллекта, машинного обучения и диалогового искусственного интеллекта, НЛП революционизирует подход медицинских работников к уходу за пациентами. Это делает медицинские рабочие процессы более эффективными и улучшает общие результаты лечения пациентов.
Внедрение извлечения сущностей на основе ИИ привело к значительному прогрессу в различных отраслях, от здравоохранения до электронной коммерции, улучшению процесса принятия решений, оптимизации процессов и повышению качества обслуживания клиентов.

Технология распознавания эмоций — это мощный инструмент, который может улучшить наше понимание человеческих эмоций и помочь нам создать персонализированный опыт в различных областях, таких как здравоохранение, образование и маркетинг.

В общем, в сфере здравоохранения полно пациентов и врачей, которые заинтересованы в том, чтобы еще раз изменить жизнь людей во всем мире. Доступ к большим наборам данных является односторонним. Искусственный интеллект будет продолжать доказывать, что будущее медицины. Как исследователи, так и разработчики должны использовать преимущества этих уникальных наборов данных, чтобы улучшить наше понимание клинических испытаний и ухода за пациентами по мере того, как мы движемся к все более взаимосвязанному будущему для всех.

Следующие пять лет принесут более оптимизированный опыт работы с искусственным интеллектом, функции безопасности, улучшающие эти взаимодействия, и многое другое. Тенденции разговорного ИИ в ближайшие несколько лет будут ярче и доступнее, чем когда-либо прежде.

Изменения продолжаются, что ведет к более прибыльному и прибыльному будущему, обеспечивающему лучший пользовательский опыт. Благодаря этим изменениям в сочетании с возможностью учиться на ошибках других компаний сектор BFSI продолжит быстро продвигаться вперед к использованию распознавания лиц — более эффективной и безопасной конечной цели для всех вовлеченных органов.

Голосовой поиск — это развивающаяся область технологий. Он медленно, но верно делает гигантские шаги, становясь более способным с помощью искусственного интеллекта, обработки естественного языка и машинного обучения. Тот тип ИИ, который существует сейчас, не является разумным; эти голосовые помощники — это инструменты, которые делают нашу жизнь лучше, проще и эффективнее.
Службы маркировки данных помогают компаниям превращать данные, у которых нет меток или тегов, в данные, которые их имеют. Они часто используют человеческую рабочую группу или машинное обучение для маркировки наборов данных, которые им предоставляют компании.

Технология распознавания голоса потенциально может произвести революцию в сфере здравоохранения несколькими способами. Обеспечивая более быструю и точную документацию, снижая риск ошибок и улучшая взаимодействие с пациентами, технология распознавания голоса может помочь поставщикам медицинских услуг оказывать более качественную помощь.

В страховой отрасли имеется много данных, но они настолько загромождены, что поиск практически невозможен. Страховая отрасль должна быть оцифрована, и теперь это возможно. С помощью оптического распознавания символов сбор и сортировка данных становятся такими же простыми, как фотографирование или ввод нескольких слов.

Банки получат положительный опыт внедрения технологий ИИ. Это основано на интервью с компаниями, которые уже используют ИИ в своих бизнес-процессах. Пока существуют меры безопасности, обеспечивающие безопасность данных клиентов и соблюдение этических стандартов, которые могут регулироваться автоматически, банкам следует внедрять ИИ в свои системы.

Влияние машинного обучения на рынок колл-центров реально и измеримо. Сбор данных в режиме реального времени и машинное обучение были объединены, чтобы сделать колл-центры еще более эффективными. Кроме того, количество голосовых решений увеличилось в Северной Америке и продолжает распространяться по всему миру.

Технология распознавания голоса становится все более важной в здравоохранении, и врачи и медсестры все чаще полагаются на нее при выполнении многих своих профессиональных обязанностей. Хотя многие вопросы еще предстоит решить, прежде чем мы увидим широкое использование этой технологии в больницах, клинических условиях и кабинетах врачей, первые признаки указывают на большие перспективы.
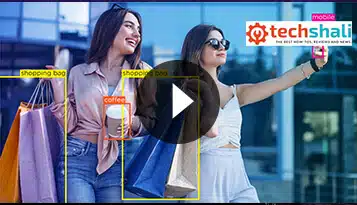
Технология видеоаннотации предназначена для обеспечения безопасности розничных систем искусственного интеллекта и клиентов. Программное обеспечение для видеоаннотаций — отличный способ сделать это, позволяя людям быстро и легко оповещать власти, когда они становятся свидетелями чего-то подозрительного в розничной торговле; помогая системам ИИ учиться на прошлом опыте, чтобы они могли адаптировать свои ответы, чтобы чувствовать себя лучше в отношении того, что считается нормальным поведением.

Случаи использования распознавания лиц могут творить чудеса при хранении и извлечении данных, но они также сопряжены с интригующим этическим затруднением. Есть ли смысл использовать такую технологию? Некоторые люди считают, что ответ «нет», особенно в отношении вторжения распознавания лиц в частную жизнь. Другие ссылаются на использование этих новых инструментов, поэтому этой технологии, возможно, не стоит избегать любой ценой.

ИИ изменит то, как мы взаимодействуем с технологиями. Как только вы привыкнете к разговорному ИИ и он станет неотъемлемой частью вашей жизни, вы удивитесь, как раньше обходились без него.

Пользовательские слова пробуждения могут помочь персонализировать ваш бренд и выделить его среди конкурентов. Есть много факторов, которые следует учитывать при выборе пользовательского слова для пробуждения. Но если вы хотите выделиться в сегодняшнем конкурентном деловом мире, стоит приложить дополнительные усилия, чтобы убедиться, что ваш голосовой помощник звучит уникально.

Новые достижения в голосовых технологиях никуда не денутся. Их популярность будет только расти, поэтому сейчас самое подходящее время, чтобы опередить конкурентов и начать создавать инновационные голосовые решения для водителей. Поскольку производители автомобилей интегрируют распознавание речи в свои автомобили, это открывает новый мир возможностей для технологии и ее пользователей.

Понятно, что пищевой ИИ будет иметь огромное влияние на то, как мы едим. От стремления сетей быстрого питания к более персонализированным меню до множества новых, инновационных ресторанов, у технологий есть бесчисленные возможности для упрощения нашего питания и улучшения качества нашей еды. С развитием алгоритмов искусственного интеллекта и машинного обучения мы можем ожидать, что интеллектуальный пищевой ИИ положительно повлияет на наше здоровье и общее экологическое воздействие нашей пищевой системы.

Таким образом, семантическая сегментация является важным сектором алгоритмов глубокого обучения, используемым для ускорения достижений в области компьютерного зрения. Семантическая сегментация будет продолжать развиваться во многих из этих связанных подкатегорий, обнаружении объектов, классификации и локализации.

В целом, эффективная система распознавания речи должна быть простой в настройке и использовании в различных ситуациях, обеспечивая при этом точные результаты без особых затруднений со стороны пользователя.

Для создания данных умного дома требуется набор процессов, которые в конечном итоге гарантируют, что алгоритм машинного обучения работает и обрабатывает данные без каких-либо сбоев.

Страховая отрасль традиционно была консервативна в отношении технологических достижений и не решалась внедрять новые технологии. Однако времена меняются, и искусственный интеллект (ИИ) привлекает большое внимание страховых компаний, которые начинают осознавать важную роль, которую ИИ может играть в их деятельности.

Сбор данных — это процесс сбора, анализа и измерения точных данных из различных систем для использования при принятии решений в бизнес-процессах, речевых проектах и исследованиях.

Банковское дело уже не то. Большинству из нас нужны быстрые, эффективные, безупречные банковские услуги, удобные и, самое главное, надежные. Имеет смысл переходить только на цифровые банковские каналы, которые могут предоставить эти вещи. Как оказалось, виртуальные помощники на основе искусственного интеллекта (ИИ) и машинного обучения (МО) могут делать именно это.

Вам когда-нибудь приходилось переводить важные электронные письма на другой язык? Если это так, вы будете разочарованы знанием того, что чья-то служба ответов на электронные письма не может быстро перевести ваши электронные письма для вас. Это может быть особенно неприятно, если коммуникация является ключевым фактором для любой организации.

Термины чат-бот и виртуальные помощники используются для создания разговоров с использованием возможностей автоматизации с человеческим прикосновением. Благодаря автономному разрешению чат-боты и виртуальные помощники также ускоряют работу сотрудников и клиентов.

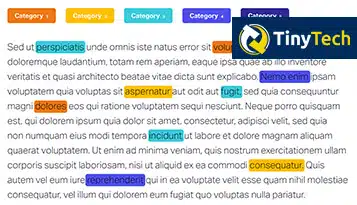
Упрощенная версия классификации документов, часто рассматриваемая как одна из подобластей классификации текстов, означает пометку документов и размещение их в предопределенных категориях с целью упрощения обслуживания и эффективного обнаружения.

Привет, Siri, не могли бы вы найти у меня хороший пост в блоге, в котором перечислены основные тенденции разговорного ИИ. Или, Алекса, можешь просто поставить мне песню, которая отвлечет меня от мирских повседневных дел. Ну, это не просто риторика, а стандартные обсуждения в гостиной, которые подтверждают общее влияние концепции, называемой разговорным ИИ.

OCR или оптическое распознавание символов — это увлекательный способ чтения и понимания документов. Но почему это вообще имеет смысл? Давай выясним. Но прежде чем мы продолжим, нам нужно вспомнить менее распространенный термин машинного обучения: RPA (роботизированная автоматизация процессов).

Жестокая правда заключается в том, что качество собранных вами обучающих данных определяет качество вашей модели распознавания речи или даже устройства. Поэтому необходимо связаться с опытными поставщиками данных, чтобы помочь вам пройти через этот процесс без особых усилий, особенно когда обучение модели или соответствующих алгоритмов требует сбора, аннотирования и других умелых стратегий.

Способность, заложенная в машины — делающая их способными взаимодействовать максимально гуманным образом, — имеет другой вид кайфа. Тем не менее, остается вопрос, как диалоговый ИИ работает в режиме реального времени и какая технология обеспечивает его существование.

Как следует из названия, синтетические данные — это данные, созданные искусственно, а не в результате реальных событий. В маркетинге, социальных сетях, здравоохранении, финансах и безопасности синтетические данные помогают создавать более инновационные решения.

Когда мы говорим об оптическом распознавании символов (OCR), это область искусственного интеллекта (ИИ), которая конкретно связана с компьютерным зрением и распознаванием образов. OCR относится к процессу извлечения информации из нескольких форматов данных, таких как изображения, PDF, рукописные заметки и отсканированные документы, и преобразования их в цифровой формат для дальнейшей обработки.

Система наблюдения за водителем — это усовершенствованная функция безопасности, в которой используется камера, установленная на приборной панели, для контроля бдительности и сонливости водителя. В случае, если водитель засыпает и отвлекается, система мониторинга водителя формирует предупреждение и рекомендует сделать перерыв.

Обработка естественного языка — это подполе искусственного интеллекта, способное разлагать человеческий язык и передавать его принципы интеллектуальным моделям. Планировали ли вы использовать НЛП в качестве технологии обучения моделей? Читайте дальше, чтобы узнать о проблемах и решениях для их решения.

Кроме того, разговорный ИИ постоянно учится на предыдущем опыте, используя наборы данных машинного обучения, чтобы предлагать информацию в реальном времени и превосходное обслуживание клиентов. Кроме того, разговорный ИИ не только вручную понимает наши запросы и отвечает на них, но также может быть подключен к другим технологиям ИИ, таким как поиск и зрение, для ускорения процесса.

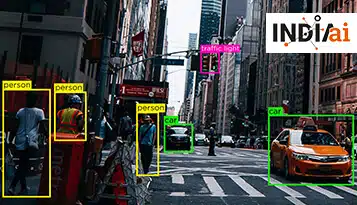
Распознавание изображений — это способность программного обеспечения идентифицировать объекты, места, людей и действия на изображениях. Используя наборы данных машинного обучения, предприятия могут использовать распознавание изображений для идентификации и классификации объектов по нескольким категориям.

Искусственный интеллект делает машины умнее, и точка! Тем не менее, то, как они это делают, столь же отличается и интригует, как и соответствующая вертикаль. Например, такие функции, как обработка естественного языка, пригодятся, если вы будете проектировать и разрабатывать остроумных чат-ботов и цифровых помощников. Точно так же, если вы хотите сделать страховой сектор более прозрачным и удобным для пользователей, Computer Vision — это субдомен ИИ, на котором вы должны сосредоточиться.

Могут ли машины обнаруживать эмоции, просто сканируя лицо? Хорошая новость в том, что они могут. И плохая новость заключается в том, что рынку еще предстоит пройти долгий путь, прежде чем он станет мейнстримом. Тем не менее, препятствия и проблемы с внедрением не мешают пропагандистам ИИ поставить «обнаружение эмоций» на карту ИИ — довольно агрессивно.

Компьютерное зрение не так широко распространено, как другие приложения ИИ, такие как обработка естественного языка. Тем не менее, он медленно поднимается в рейтингах, что делает 2022 год захватывающим годом для более масштабного внедрения. Вот некоторые из перспективных возможностей компьютерного зрения (в основном домены), которые, как ожидается, будут лучше изучены бизнесом в 2022 году.

Предприятия по всему миру переходят от бумажных документов к цифровой обработке данных. Но что такое OCR? Как это работает? И в каком бизнес-процессе можно использовать его преимущества? Давайте углубимся в эту статью и выясним, какие преимущества дает OCR.

Ответ — автоматическое распознавание речи (ASR). Это огромный шаг, чтобы преобразовать устное слово в письменную форму. Автоматическое распознавание речи (ASR) — это тенденция, которая должна стать шумной в 2022 году. Рост числа голосовых помощников обусловлен появлением встроенных голосовых помощников в смартфонах и интеллектуальных голосовых устройствах, таких как Alexa.
Вы ищете мозги лучших моделей искусственного интеллекта? Что ж, поклонитесь аннотаторам данных. Несмотря на то, что аннотация данных занимает центральное место в подготовке ресурсов, относящихся к каждой вертикали, управляемой ИИ, мы рассмотрим эту концепцию и узнаем больше о главных героях маркировки с точки зрения ИИ в здравоохранении.

И вы не находите захватывающим, если покупатели оплачивают счет на кассе, просто изображая лицо, а не карту или бумажник? Распознавание лиц позволяет ритейлерам анализировать настроения и предпочтения покупателей на основе их прошлых покупок.

Как финансовые организации могут обеспечить максимальную конверсию продаж и прием платежей, а также свести к минимуму подверженность рискам с ростом количества цифровых платежей, совершаемых во всем мире? Звучит тревожно? В финансовой отрасли, которая сильно зависит от обработки данных и информации, поддержание предельного преимущества и понимание естественных нюансов клиентов для обеспечения своевременного решения требует технологии, связанной с искусственным интеллектом.

Дроны являются жизнеспособным инструментом для сбора данных и предоставляют информацию в режиме реального времени. Использование аналитики данных упрощает осмотр мостов, добычу полезных ископаемых и прогноз погоды.

Анализ настроений колл-центра — это обработка данных путем выявления естественных нюансов контекста клиента и анализа данных, чтобы сделать обслуживание клиентов более чутким.

Ну, первая причина не нуждается в подтверждении. Проекты машинного обучения требуют алгоритмов, сбора данных, высококачественных аннотаций и других сложных аспектов.

Являясь ветвью искусственного интеллекта, НЛП направлено на то, чтобы заставить машины реагировать на человеческий язык. Что касается технического аспекта, НЛП вполне уместно использует информатику, лингвистику, алгоритмы и общую языковую структуру, чтобы сделать машины разумными. Проактивные и интуитивно понятные машины, когда бы они ни были построены, могут извлекать, анализировать и понимать истинное значение и контекст речи и даже текста.

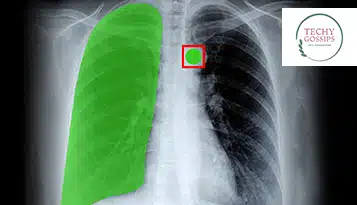
Именно здесь аннотация медицинских изображений может сыграть свою роль, поскольку она эффективно передает необходимые знания медицинским диагностическим установкам на базе искусственного интеллекта для дальнейшего использования точного компьютерного зрения в качестве базовой технологии разработки моделей.

Искусственный интеллект не должен быть мрачной темой для обсуждения. Обладая возможностями стать самым преобразующим инструментом в ближайшие годы, ИИ быстро превращается в вспомогательный ресурс, вместо того чтобы оставаться на курсе как подавляющая технология.

Знаете ли вы о технических особенностях, связанных с созданием целостных, интуитивно понятных и эффективных моделей машинного обучения? Если нет, то вам сначала нужно понять, как каждый процесс можно разделить на три фазы, т. е. развлечение, функциональность и изящество. В то время как «Изящество» касается доведения алгоритмов машинного обучения до совершенства, сначала разрабатывая сложные программы с использованием соответствующих языков программирования, «Развлечение» заключается в том, чтобы сделать клиентов счастливыми, предлагая им проницательный и интеллектуальный забавный продукт.

Представьте, что вы просыпаетесь в один прекрасный день и видите, что все ваши кухонные контейнеры выставлены на продажу в черном цвете, и вы не видите, что внутри. И тогда найти кубики сахара для чая будет проблемой. При условии, что вы можете найти чай в первую очередь.

Аннотации данных - это просто процесс маркировки информации, чтобы машины могли ее использовать. Это особенно полезно для машинного обучения с учителем (ML), когда система полагается на помеченные наборы данных для обработки, понимания и изучения шаблонов ввода для достижения желаемых результатов.

Маркировка данных не так уж и сложна, - сказала ни одна организация! Но, несмотря на трудности, возникающие на пути, не многие понимают сложность стоящих перед ними задач. Маркировка наборов данных, особенно для того, чтобы они подходили для моделей искусственного интеллекта и машинного обучения, - это то, что требует многолетнего опыта и практического доверия. И в довершение ко всему, маркировка данных не является одномерным подходом и зависит от типа модели, над которой работает.

Сбор данных для речевых проектов упрощается, если вы применяете систематический подход. Прочтите наш эксклюзивный пост о сборе данных для речевых проектов и получите ясность.

Проще говоря, текстовые аннотации предназначены для маркировки определенных документов, цифровых файлов и даже связанного с ними контента. После того, как эти ресурсы помечены или помечены, они становятся понятными и могут быть развернуты алгоритмами машинного обучения для обучения моделей до совершенства.

Сегодня мы выбрали Ватсал Гийя для интервью. Ватсал Гия - серийный предприниматель с более чем 20-летним опытом работы в сфере программного обеспечения и услуг на основе искусственного интеллекта в сфере здравоохранения. Он является генеральным директором и соучредителем Shaip, который позволяет масштабировать нашу платформу, процессы и людей по запросу для компаний с наиболее требовательными инициативами в области машинного обучения и искусственного интеллекта.

Финансовые услуги со временем претерпели изменения. Всплеск мобильных платежей, решений для личного банковского обслуживания, улучшенного кредитного мониторинга и других финансовых схем еще больше гарантирует, что сфера, касающаяся денежных вложений, не такая, какой она была несколько лет назад. В 2021 году речь идет не только о «финансовом секторе» или «финансах», но и обо всех «финансовых технологиях» с революционными финансовыми технологиями, которые почувствуют свое присутствие, чтобы изменить качество обслуживания клиентов, методы работы соответствующих организаций или, если быть точным, всю финансовую арену.
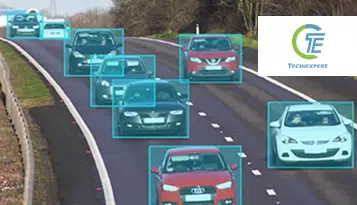
Несмотря на своевременный подъем автомобильной промышленности, вертикаль оставляет много возможностей для постепенных улучшений. Начиная от снижения количества дорожно-транспортных происшествий и заканчивая улучшением производства транспортных средств и развертыванием ресурсов, искусственный интеллект кажется наиболее вероятным решением, позволяющим добиться успеха в небесах.

В наши дни искусственный интеллект больше похож на маркетинговый жаргон. Каждая известная вам компания, стартап или бизнес продвигает свои продукты и услуги, используя в качестве УТП термин «на базе искусственного интеллекта». Верно этому, искусственный интеллект сегодня кажется неизбежным. Если вы заметили, почти все, что у вас есть вокруг, работает на искусственном интеллекте. Сегодня искусственный интеллект - от систем рекомендаций на Netflix и алгоритмов в приложениях для знакомств до самых сложных организаций в секторе здравоохранения, которые помогают в онкологии.

У машинного обучения, вероятно, самые смешанные определения и интерпретации в мире. То, что несколько лет назад стало модным словом, продолжает сбивать с толку многих людей благодаря тому, как это было изображено и преподнесено.

Искусственный интеллект (ИИ) амбициозен и чрезвычайно полезен для развития человечества. В такой сфере, как здравоохранение, особенно в сфере здравоохранения, искусственный интеллект вносит заметные изменения в наши подходы к диагностике заболеваний, их лечению, уходу за пациентами и их мониторингу. Не забывайте об исследованиях и разработках, связанных с разработкой новых лекарств, новых способов выявления проблем и основных состояний и многого другого.

Здравоохранение как вертикаль никогда не было статичным. Но с другой стороны, никогда не было такой динамики из-за слияния разрозненных медицинских открытий, заставляющих нас безжалостно смотреть на груды неструктурированных данных. Честно говоря, гигантский объем данных больше не проблема. Это реальность, которая к концу 2,000 года даже превысила отметку в 2020 эксабайт.

Искусственный интеллект - это технология, которая позволяет машинам имитировать поведение человека. Все дело в том, чтобы научить машины учиться и думать автономно, а также использовать результаты, чтобы реагировать и реагировать соответствующим образом.

Каждый раз, когда ваша система GPS-навигатора просит вас объехать, чтобы избежать движения, поймите, что такой точный анализ и результаты приходят после нескольких сотен часов тренировок. Всякий раз, когда ваше приложение Google Lens точно идентифицирует объект или продукт, помните, что тысячи изображений после тысяч были обработаны его модулем AI (искусственный интеллект) для точной идентификации.

4 основных вещи, которые нужно знать о деидентификации данных. Поскольку данные генерируются со скоростью 2.5 квинтиллиона байт каждый день, мы, как пользователи Интернета, генерируем почти 1.7 МБ каждую секунду в 2020 году.

Теперь, когда вся планета подключена к сети и подключена к сети, мы коллективно генерируем неизмеримые объемы данных. Отрасль, бизнес, сегмент рынка или любой другой субъект будут рассматривать данные как единое целое. Тем не менее, с точки зрения частных лиц, данные лучше называть нашим цифровым следом.

Качественные данные превращаются в истории успеха, в то время как низкое качество данных является хорошим примером. Некоторые из наиболее эффективных тематических исследований функциональности ИИ возникли из-за отсутствия качественных наборов данных. Хотя все компании воодушевлены и амбициозны в отношении своих проектов и продуктов в области ИИ, это волнение никак не отражается на методах сбора данных и обучения. Уделяя больше внимания выпуску, чем обучению, некоторые компании в конечном итоге откладывают выход на рынок, теряют финансирование или даже опускают ставни на вечность.

Процесс аннотирования или пометки сгенерированных данных позволяет алгоритмам машинного обучения и искусственного интеллекта эффективно идентифицировать каждый тип данных и решать, что из них извлекать и что с ними делать. Чем более четко определен или маркирован каждый набор данных, тем лучше алгоритмы могут обработать его для получения оптимальных результатов.
Алекса, есть ли рядом со мной суши? Часто мы часто задаем нашим виртуальным помощникам открытые вопросы. Задавать подобные вопросы другим людям понятно, учитывая то, как мы привыкли разговаривать и взаимодействовать. Однако задавать очень простой вопрос в разговорной речи машине, которая почти не разбирается в языке и тонкостях разговора, не имеет никакого смысла, верно?

Что ж, за каждым таким удивительным инцидентом стоят такие концепции, как искусственный интеллект, машинное обучение и, самое главное, NLP (обработка естественного языка). Одним из самых больших достижений нашего времени является НЛП, где машины постепенно развиваются, чтобы понимать, как люди говорят, эмоции, понимают, реагируют, анализируют и даже имитируют человеческие разговоры и поведение, основанное на чувствах. Эта концепция оказала большое влияние на разработку чат-ботов, инструментов преобразования текста в речь, распознавания голоса, виртуальных помощников и многого другого.

Несмотря на то, что концепция искусственного интеллекта (ИИ) была введена в 1950-х годах, ее имя стало нарицательным лишь пару лет назад. Эволюция ИИ была постепенной, и потребовалось почти шесть десятилетий, чтобы предложить безумные функции и возможности, которые он делает сегодня. Все это стало невероятно возможным благодаря одновременной эволюции аппаратной периферии, технической инфраструктуры, смежных концепций, таких как облачные вычисления, системы хранения и обработки данных (большие данные и аналитика), проникновения и коммерциализации Интернета и многого другого. Все вместе привело к этому удивительному этапу технологической временной шкалы, когда ИИ и машинное обучение (ML) не только стимулируют инновации, но и становятся неизбежными концепциями, без которых можно жить.

Каждой системе искусственного интеллекта необходимы огромные объемы качественных данных для обучения и получения точных результатов. В этом предложении есть два ключевых слова - огромные объемы и качественные данные. Давайте обсудим оба по отдельности.

Все разговоры и дискуссии о развертывании искусственного интеллекта для бизнеса и операций носили лишь поверхностный характер. Некоторые говорят о преимуществах их внедрения, а другие обсуждают, как модуль ИИ может повысить производительность на 40%. Но мы вряд ли решаем реальные проблемы, связанные с их включением в наши бизнес-цели.
Трудно представить борьбу с глобальной пандемией без таких технологий, как искусственный интеллект (AI) и машинное обучение (ML). Экспоненциальный рост случаев Covid-19 во всем мире парализовал многие инфраструктуры здравоохранения. Однако учреждения, правительства и организации смогли дать отпор с помощью передовых технологий. Искусственный интеллект и машинное обучение, которые когда-то считались роскошью для улучшения образа жизни и повышения производительности, стали спасательными средствами в борьбе с Covid благодаря своим бесчисленным приложениям.

Определенные группы людей испытывают боль сильнее. Исследования показали, что люди из меньшинств и обездоленных групп, как правило, испытывают больше физической боли, чем население в целом, из-за стресса, общего состояния здоровья и других факторов.

Прежде чем вы даже планируете получать данные, одно из наиболее важных соображений при определении того, сколько вы должны потратить на данные для обучения ИИ. В этой статье мы расскажем, как разработать эффективный бюджет для данных обучения ИИ.

Shaip - это онлайн-платформа, которая специализируется на решениях для обработки данных искусственного интеллекта в сфере здравоохранения и предлагает лицензированные медицинские данные, предназначенные для построения моделей искусственного интеллекта. Он предоставляет текстовые медицинские записи пациентов и данные требований, аудио, такие как записи врача или разговоры пациента / врача, а также изображения и видео в виде рентгеновских снимков, компьютерной томографии и результатов МРТ.

Данные - один из важнейших элементов при разработке алгоритма искусственного интеллекта. Помните, что тот факт, что данные генерируются быстрее, чем когда-либо, не означает, что нужные данные легко найти. Низкокачественные, предвзятые или неправильно аннотированные данные могут (в лучшем случае) добавить еще один шаг. Эти дополнительные шаги замедлят вас, потому что команды разработчиков и специалистов по обработке данных должны проработать их на пути к функциональному приложению.

Многое было сказано о потенциале искусственного интеллекта для преобразования отрасли здравоохранения, и не зря. Сложные платформы искусственного интеллекта опираются на данные, и организации здравоохранения имеют их в изобилии. Так почему же отрасль отстает от других с точки зрения внедрения ИИ? Это многогранный вопрос с множеством возможных ответов. Однако все они, несомненно, будут указывать на одно препятствие: большие объемы неструктурированных данных.

Однако то, что кажется простым, утомительно для разработки и развертывания, как и любую другую сложную систему искусственного интеллекта. Прежде чем ваше устройство смогло распознать захваченное вами изображение и модули машинного обучения (ML) смогли его обработать, аннотатор данных или их команда потратили бы тысячи часов на аннотирование данных, чтобы сделать их понятными для машин.

В этом специальном гостевом репортаже Ватсал Гия, генеральный директор и соучредитель Shaip, исследует три фактора, которые, по его мнению, позволят ИИ, основанному на данных, полностью раскрыть свой потенциал в будущем: талант и ресурсы, необходимые для создания инновационных алгоритмов, огромный объем данных для точного обучения этих алгоритмов и достаточная вычислительная мощность для эффективного анализа этих данных. Ватсал - серийный предприниматель с более чем 20-летним опытом работы в сфере программного обеспечения и услуг на базе искусственного интеллекта в сфере здравоохранения. Shaip позволяет масштабировать свою платформу, процессы и людей по требованию для компаний с наиболее требовательными инициативами в области машинного обучения и искусственного интеллекта.

Процессы в системах искусственного интеллекта (ИИ) эволюционируют. В отличие от других продуктов, услуг или систем, представленных на рынке, модели искусственного интеллекта не предлагают мгновенных вариантов использования или мгновенных 100% точных результатов. Результаты развиваются по мере более тщательной обработки актуальных и качественных данных. Это похоже на то, как ребенок учится говорить или как музыкант начинает с изучения первых пяти основных аккордов, а затем развивает их. Достижения не открываются в одночасье, но тренировки для достижения совершенства происходят постоянно.

Когда мы говорим об искусственном интеллекте (AI) и машинном обучении (ML), мы сразу представляем себе мощные технологические компании, удобные и футуристические решения, модные беспилотные автомобили и практически все, что эстетично, творчески и интеллектуально приятно. То, что вряд ли проецируется на людей, - это реальный мир, скрывающийся за всеми удобствами и жизненным опытом, предлагаемыми ИИ.

Эксклюзивное интервью, в котором Утсав, руководитель бизнеса - Shaip общается с Сунил, исполнительным редактором My Startup, чтобы рассказать ему о том, как Shaip улучшает человеческую жизнь, решая проблемы будущего с помощью своих предложений Conversational AI и Healthcare AI. Далее он заявляет, что AI, ML революционизируют способы ведения бизнеса и как Shaip внесет свой вклад в развитие технологий следующего поколения.
Искусственный интеллект (ИИ) улучшает наш образ жизни за счет более точных рекомендаций фильмов, ресторанов, разрешения конфликтов с помощью чат-ботов и многого другого. Сила, потенциал и возможности ИИ все чаще находят хорошее применение в различных отраслях и областях, о которых, вероятно, никто не задумывался. Фактически, ИИ изучается и внедряется в таких областях, как здравоохранение, розничная торговля, банковское дело, уголовное правосудие, наблюдение, прием на работу, устранение разрыва в заработной плате и т. Д.

Мы все видели, что происходит, когда разработка ИИ идет наперекосяк. Рассмотрим попытку Amazon создать систему набора персонала с использованием ИИ, которая была отличным способом сканировать резюме и определять наиболее квалифицированных кандидатов - при условии, что эти кандидаты были мужчинами.

В прошлом году отрасль здравоохранения подверглась испытаниям из-за пандемии, и в ней проявилось множество инноваций - от новых лекарств и медицинских устройств до прорывов в цепочке поставок и улучшения процессов сотрудничества. Руководители предприятий из всех областей отрасли нашли новые способы ускорения роста для поддержки общего блага и получения критически важных доходов.

Мы видели их в фильмах, читали о них в книгах и испытывали их в реальной жизни. Как бы фантастично это ни казалось, мы должны смотреть правде в глаза - распознавание лиц никуда не денется. Технология развивается динамично, и с учетом разнообразных вариантов использования, возникающих в разных отраслях, широкий спектр разработок в области распознавания лиц кажется просто неизбежным и бесконечным.

Многоязычные чат-боты меняют деловой мир. Чат-боты прошли долгий путь с самого начала, когда давали простые ответы из одного слова. Чат-бот теперь может свободно общаться на десятках языков, что позволяет предприятиям выйти на более широкий глобальный рынок.

Здравоохранение часто считают отраслью, находящейся на переднем крае технологических инноваций. Это верно во многих отношениях, но сфера здравоохранения также строго регулируется широким законодательством, таким как GDPR и HIPAA, а также множеством других местных правил и ограничений.

Отчет за 2018 год показал, что мы генерируем около 2.5 квинтиллионов байтов данных каждый день. Вопреки распространенному мнению, не все данные, которые мы генерируем, могут быть обработаны для анализа.

Искусственный интеллект с каждым днем становится умнее. Сегодня мощные алгоритмы машинного обучения доступны для обычных предприятий, а алгоритмы, требующие вычислительной мощности, которые раньше были зарезервированы для массивных мэйнфреймов, теперь могут быть развернуты на доступных облачных серверах.