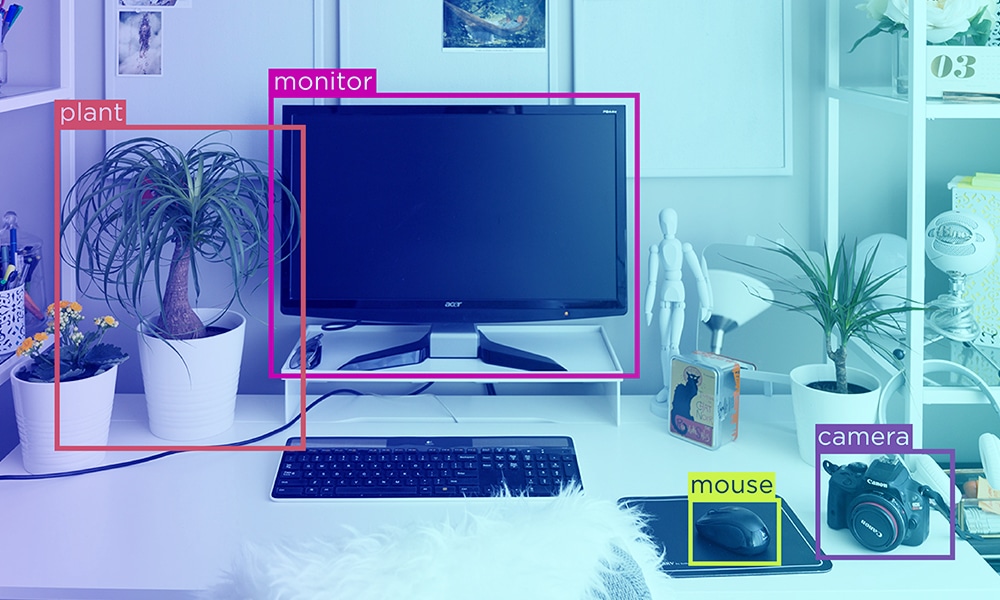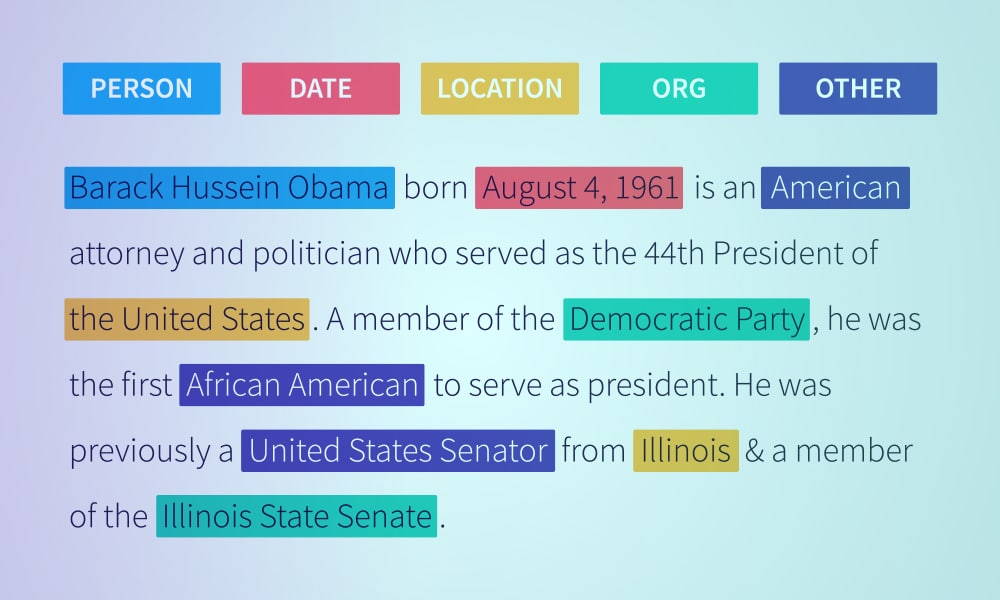
Данные — это сверхдержава, которая трансформирует цифровой ландшафт в современном мире. От электронных писем до постов в социальных сетях данные есть везде. Это правда, что предприятия никогда не имели доступа к такому большому количеству данных, но достаточно ли иметь доступ к данным? Богатый источник информации становится бесполезным или устаревшим, если он не обрабатывается.
Неструктурированный текст может быть богатым источником информации, но он будет бесполезен для бизнеса, если данные не будут организованы, классифицированы и проанализированы. Неструктурированные данные, такие как текст, аудио, видео и социальные сети, составляют 80-90% всех данных. Более того, по сообщениям, едва ли 18% организаций используют преимущества неструктурированных данных своей организации.
Вручную просеивать терабайты данных, хранящихся на серверах, — трудоемкая и откровенно невыполнимая задача. Однако благодаря достижениям в области машинного обучения, обработки естественного языка и автоматизации стало возможным быстро и эффективно структурировать и анализировать текстовые данные. Первым шагом в анализе данных является классификация текста.
Что такое классификация текстов?
Классификация или категоризация текста — это процесс группировки текста в заранее определенные категории или классы. Используя этот подход машинного обучения, любой текст — документы, веб-файлы, исследования, юридические документы, медицинские заключения и т. д. – могут быть классифицированы, организованы и структурированы.
Классификация текста — это основной этап обработки естественного языка, который имеет несколько применений при обнаружении спама. Анализ настроений, обнаружение намерений, маркировка данных и многое другое.
Возможные варианты использования классификации текста
 Использование классификации текста с помощью машинного обучения имеет несколько преимуществ, таких как масштабируемость, скорость анализа, согласованность и возможность принимать быстрые решения на основе разговоров в реальном времени.
Использование классификации текста с помощью машинного обучения имеет несколько преимуществ, таких как масштабируемость, скорость анализа, согласованность и возможность принимать быстрые решения на основе разговоров в реальном времени.
Когда модель машинного обучения обучается на ИИ, который автоматически классифицирует элементы по заранее заданным категориям, вы можете быстро превратить случайных посетителей в клиентов.
Процесс классификации текста
Процесс классификации текста начинается с предварительной обработки, выбора признаков, извлечения и классификации данных.

Предварительная обработка
лексемизация: Текст разбивается на более мелкие и простые текстовые формы для облегчения классификации.
Нормализация: Весь текст в документе должен быть на одном уровне понимания. Некоторые формы нормализации включают,
- Соблюдение грамматических или структурных стандартов в тексте, например удаление пробелов или знаков препинания. Или сохранение строчных букв по всему тексту.
- Удаление приставок и суффиксов из слов и приведение их к их корневому слову.
- Удаление стоп-слов, таких как «и», «есть», «то» и других, которые не добавляют ценности тексту.
Выбор функций
Выбор признаков является фундаментальным шагом в классификации текста. Процесс направлен на представление текстов с наиболее релевантным признаком. Выбор функций помогает удалить ненужные данные и повысить точность.
Выбор признаков уменьшает входную переменную в модель, используя только наиболее релевантные данные и устраняя шум. В зависимости от типа решения, которое вы ищете, ваши модели ИИ могут быть разработаны таким образом, чтобы выбирать из текста только соответствующие функции.
Функция извлечения
Извлечение признаков — это необязательный шаг, который предпринимают некоторые компании для извлечения дополнительных ключевых признаков из данных. Извлечение признаков использует несколько методов, таких как сопоставление, фильтрация и кластеризация. Основное преимущество использования извлечения признаков заключается в том, что оно помогает удалить избыточные данные и повысить скорость разработки модели машинного обучения.
Пометка данных по заранее определенным категориям
Пометка текста предопределенными категориями является последним шагом в классификации текста. Это можно сделать тремя разными способами,
- Маркировка вручную
- Сопоставление на основе правил
- Алгоритмы обучения. Алгоритмы обучения можно разделить на две категории, такие как контролируемая маркировка и неконтролируемая маркировка.
- Контролируемое обучение: модель машинного обучения может автоматически согласовывать теги с существующими категоризированными данными при контролируемом тегировании. Когда классифицированные данные уже доступны, алгоритмы машинного обучения могут отображать функцию между тегами и текстом.
- Неконтролируемое обучение: это происходит, когда не хватает ранее существующих помеченных данных. В моделях машинного обучения используются алгоритмы кластеризации и алгоритмы на основе правил для группировки похожих текстов, например, на основе истории покупок продуктов, отзывов, личных данных и билетов. Эти широкие группы можно дополнительно проанализировать, чтобы получить ценную информацию о конкретных клиентах, которую можно использовать для разработки индивидуальных подходов к клиентам.
Существует несколько вариантов использования классификации текста в разных отраслях. Хотя сбор, группировка, классификация и извлечение ценных сведений из текстовых данных всегда использовались в нескольких областях, классификация текстов находит свой потенциал в маркетинге, разработке продуктов, обслуживании клиентов, управлении и администрировании. Это помогает предприятиям получать информацию о конкурентах, рынке и клиентах, а также принимать бизнес-решения на основе данных.
Разработать эффективный и содержательный инструмент классификации текста непросто. Тем не менее, с Shaip в качестве вашего партнера по данным вы можете разработать эффективный, масштабируемый и экономичный инструмент классификации текста на основе ИИ. У нас есть тонны точно аннотированные и готовые к использованию наборы данных которые могут быть настроены в соответствии с уникальными требованиями вашей модели. Превращаем ваш текст в конкурентное преимущество; свяжитесь сегодня.