
Интернет открыл двери для людей, свободно выражающих свои мнения, взгляды и предложения практически по любому вопросу в мире. социальные сети, веб-сайты и блоги. Люди (клиенты) не только высказывают свое мнение, но и влияют на решения других о покупке. Настроение, будь то отрицательное или положительное, имеет решающее значение для любого бизнеса или бренда, заинтересованного в продажах своих продуктов или услуг.
Помощь предприятиям в добыче комментариев для использования в бизнесе Обработка естественного языка. Каждое четвертое предприятие планирует внедрить технологию НЛП в течение следующего года для принятия бизнес-решений. Используя анализ настроений, NLP помогает компаниям получать интерпретируемые идеи из необработанных и неструктурированных данных.
Анализ мнений или анализ настроений техника НЛП, используемая для определения точного настроения – положительный, отрицательный или нейтральный – связанные с комментариями и отзывами. С помощью НЛП анализируются ключевые слова в комментариях, чтобы определить положительные или отрицательные слова, содержащиеся в ключевом слове.
Настроения оцениваются по системе шкалы, которая присваивает оценки настроений эмоциям в фрагменте текста (определяя текст как положительный или отрицательный).
Что такое многоязычный анализ настроений?

Как следует из названия, многоязычный анализ настроений - это метод оценки тональности для более чем одного языка. Однако это не так просто. Наша культура, язык и опыт сильно влияют на наше покупательское поведение и эмоции. Без хорошего понимания языка, контекста и культуры пользователя невозможно точно понять его намерения, эмоции и интерпретации.
Хотя автоматизация является ответом на многие наши современные проблемы, машинный перевод программное обеспечение не сможет уловить нюансы языка, разговорные выражения, тонкости и культурные отсылки в комментариях и Продукт отзывов это перевод. Инструмент ML может дать вам перевод, но он может оказаться бесполезным. Вот почему требуется многоязычный анализ тональности.
Зачем нужен многоязычный анализ настроений?
Большинство предприятий используют английский язык в качестве средства общения, но он не используется большинством потребителей во всем мире.
По данным Ethnologue, около 13% населения мира говорит по-английски. Кроме того, Британский совет заявляет, что около 25% населения мира неплохо понимают английский язык. Если верить этим цифрам, то большая часть потребителей взаимодействует друг с другом и с бизнесом не на английском языке.
Если основная цель бизнеса состоит в том, чтобы сохранить свою клиентскую базу и привлечь новых клиентов, она должна глубоко понимать мнения своих клиентов, выраженные в их родной язык. Вручную просматривать каждый комментарий или переводить его на английский язык — трудоемкий процесс, который не даст эффективных результатов.
Устойчивое решение заключается в разработке многоязычного системы анализа настроений которые обнаруживают и анализируют мнения, эмоции и предложения клиентов в социальных сетях, форумах, опросах и т. д.
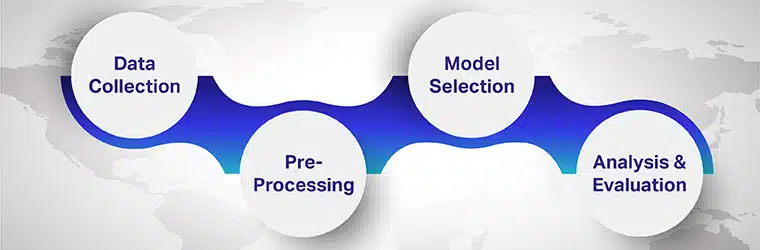
Шаги для выполнения многоязычного анализа тональности
Анализ настроений, независимо от того, на одном ли языке или несколько языков, — это процесс, который требует применения моделей машинного обучения, обработки естественного языка и методов анализа данных для извлечения многоязычная оценка тональности из данных.
Шаги, связанные с многоязычным анализом тональности:
Шаг 1: Сбор данных
Сбор данных — это первый шаг в применении анализа настроений. Для создания многоязычного модель анализа настроений, важно получать данные на разных языках. Все будет зависеть от качества собранных, аннотированных и маркированных данных. Вы можете получать данные из API, репозиториев с открытым исходным кодом и издателей.
Шаг 2: Предварительная обработка
Собранные веб-данные должны быть очищены, а информация извлечена из них. Части текста, не несущие особого смысла, такие как «the», «is» и т. д., должны быть удалены. Кроме того, текст должен быть сгруппирован в группы слов для категоризации, чтобы передать положительное или отрицательное значение.
Чтобы улучшить качество классификации, контент должен быть очищен от шума, такого как HTML-теги, реклама и скрипты. Язык, лексика и грамматика, используемые людьми, различаются в зависимости от социальной сети. Важно нормализовать такой контент и подготовить его к предварительной обработке.
Еще одним важным шагом в предварительной обработке является использование обработки естественного языка для разделения предложений, удаления стоп-слов, маркировки частей речи, преобразования слов в их корневую форму и разбиения слов на символы и текст.
Шаг 3: Выбор модели
Модель на основе правил: Самый простой метод многоязычного семантического анализа основан на правилах. Алгоритм на основе правил выполняет анализ на основе набора заранее определенных правил, запрограммированных экспертами.
Правило может указывать слова или фразы, которые являются положительными или отрицательными. Например, если вы возьмете обзор продукта или услуги, он может содержать положительные или отрицательные слова, такие как «отлично», «медленно», «подождите» и «полезно». Этот метод упрощает классификацию слов, но он может неправильно классифицировать сложные или менее часто встречающиеся слова.
Автоматическая модель: Автоматическая модель выполняет многоязычный анализ тональности без участия модераторов-людей. Хотя модель машинного обучения построена с использованием человеческих усилий, она может работать автоматически для получения точных результатов после разработки.
Тестовые данные анализируются, и каждый комментарий вручную помечается как положительный или отрицательный. Затем модель ML будет учиться на тестовых данных, сравнивая новый текст с существующими комментариями и классифицируя их.
Шаг 4: Анализ и оценка
Модели на основе правил и машинного обучения можно улучшать и улучшать с течением времени и опытом. Лексикон менее часто используемых слов или живые оценки многоязычных настроений могут быть обновлены для более быстрой и точной классификации.
Проблема перевода
Перевода не достаточно? Вообще-то, нет!
Перевод подразумевает перенос текста или групп текстов с одного языка и поиск эквивалента на другом. Однако перевод не является ни простым, ни эффективным.
Это потому, что люди используют язык не только для того, чтобы сообщать о своих потребностях, но и для выражения своих эмоций. Более того, существуют резкие различия между разными языками, такими как английский, хинди, китайский и тайский. Добавьте к этой литературной смеси использование эмоций, сленга, идиом, сарказма и смайликов. Невозможно получить точный перевод текста.
Некоторые из основных проблем машинный перевод Он
- Субъективность
- Контекст
- Сленг и идиомы
- Сарказм
- Сравнения
- нейтральность
- Смайлики и современное использование слов.
Без точного понимания предполагаемого значения обзоров, комментариев и сообщений о своих продуктах, ценах, услугах, функциях и качестве предприятия не смогут понять потребности и мнения клиентов.
Многоязычный анализ настроений — сложный процесс. Каждый язык имеет свою уникальную лексику, синтаксис, морфологию и фонологию. Добавьте к этому культуру, сленг, чувства, выраженные, сарказм и тональность, и вы получили сложную головоломку, для которой требуется эффективное решение для машинного обучения на основе искусственного интеллекта.
Для разработки надежных многоязычных инструменты анализа настроений которые могут обрабатывать отзывы и предоставлять бизнесу ценную информацию. Shaip является лидером рынка в предоставлении отраслевых наборов данных с маркировкой и аннотациями на нескольких языках, которые помогают в разработке эффективных и точных многоязычные решения для анализа настроений.


