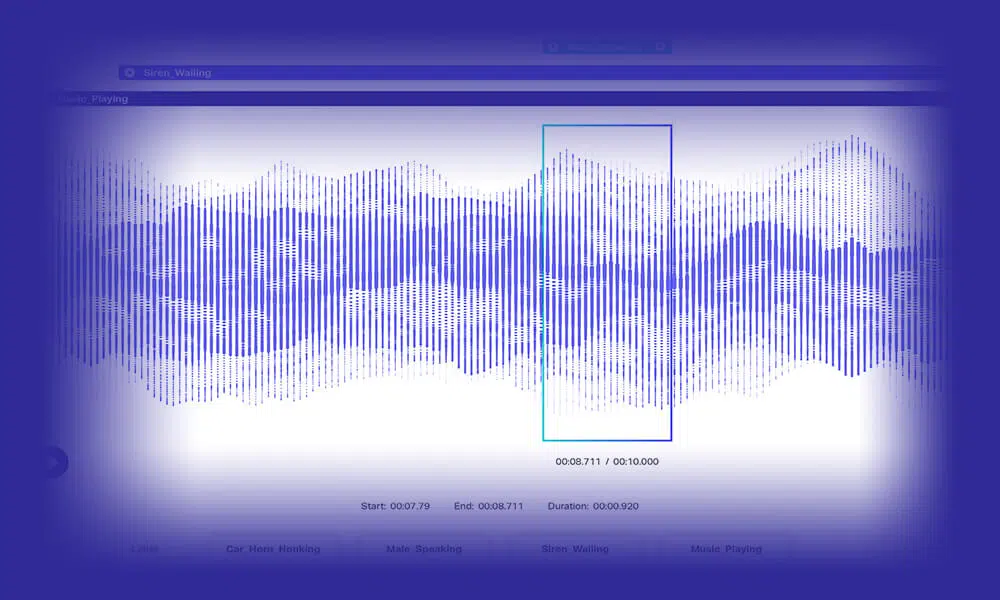


Аудио транскрипция
Разрабатывайте интеллектуальные модели НЛП, загружая грузовики точно записанными речевыми / аудиоданными. В Shaip мы предоставляем вам возможность выбирать из более широкого набора вариантов, включая стандартное аудио, дословную и многоязычную транскрипцию. Кроме того, вы можете обучать модели с дополнительными идентификаторами выступающих и данными с отметками времени.
Речевая маркировка
Маркировка речи или звука - это стандартный метод аннотации, который касается разделения звуков и маркировки с помощью определенных метаданных. Суть этой техники включает в себя онтологическую идентификацию звуков из части аудио и точное аннотирование их, чтобы сделать обучающие наборы данных более инклюзивными.

Классификация аудио
Он используется компаниями, занимающимися аннотацией речи, чтобы довести ИИ до совершенства, что касается анализа аудиозаписей в соответствии с их содержанием. С классификацией звука машины могут идентифицировать голоса и звуки, в то же время имея возможность различать их, в рамках более активного режима тренировки.

Многоязычные службы аудиоданных
Сбор многоязычных аудиоданных полезен только в том случае, если аннотаторы могут соответствующим образом маркировать и сегментировать их. Вот где пригодятся многоязычные службы аудиоданных, поскольку они касаются аннотирования речи на основе разнообразия языков, чтобы их могли точно идентифицировать и анализировать соответствующие ИИ.

Естественный язык
произнесение
NLU касается аннотирования человеческой речи для классификации мельчайших деталей, таких как семантика, диалекты, контекст, ударение и многое другое. Эта форма аннотированных данных имеет смысл для лучшего обучения виртуальных помощников и чат-ботов.
Мульти-этикетки
аннотирование
Аннотирование аудиоданных с помощью нескольких меток важно для помощи моделям в различении перекрывающихся источников звука. В этом подходе набор аудиоданных может принадлежать одному или нескольким классам, которые необходимо явно передать модели для лучшего принятия решений.

Диаризация спикера
Он включает в себя разделение входного аудиофайла на однородные сегменты, связанные с отдельными динамиками. Диаризация означает определение границ говорящих и группировку аудиофайлов в сегменты для определения количества отдельных говорящих. Этот процесс помогает автоматизировать анализ разговоров и расшифровку диалогов колл-центра, медицинских и юридических разговоров и совещаний.

Фонетическая транскрипция
В отличие от обычной транскрипции, которая преобразует звук в последовательность слов, фонетическая транскрипция отмечает, как слова произносятся, и визуально представляет звуки с помощью фонетических символов. Фонетическая транскрипция позволяет легче заметить разницу в произношении одного и того же языка в нескольких диалектах.

Люди
Выделенные и обученные команды:
- Более 30,000 сотрудников по созданию, маркировке и контролю качества данных
- Аттестованная команда управления проектами
- Опытная команда по разработке продуктов
- Команда поиска и адаптации кадрового резерва

Обработка
Наивысшая эффективность процесса обеспечивается:
- Надежный 6-сигма-технологический процесс
- Специальная команда «черных поясов 6 сигм» - владельцы ключевых процессов и соблюдение требований к качеству
- Непрерывное совершенствование и обратная связь

Платформа
Запатентованная платформа предлагает преимущества:
- Сквозная веб-платформа
- Безупречное качество
- Быстрее ТАТ
- Бесшовная доставка
Люди
Выделенные и обученные команды:
- Более 30,000 сотрудников по созданию, маркировке и контролю качества данных
- Аттестованная команда управления проектами
- Опытная команда по разработке продуктов
- Команда поиска и адаптации кадрового резерва
Обработка
Наивысшая эффективность процесса обеспечивается:
- Надежный 6-сигма-технологический процесс
- Специальная команда «черных поясов 6 сигм» - владельцы ключевых процессов и соблюдение требований к качеству
- Непрерывное совершенствование и обратная связь
Платформа
Запатентованная платформа предлагает преимущества:
- Сквозная веб-платформа
- Безупречное качество
- Быстрее ТАТ
- Бесшовная доставка

Текстовая аннотация
Услуги
Мы специализируемся на подготовке текстовых данных для обучения, аннотируя исчерпывающие наборы данных, используя аннотации сущностей, текстовую классификацию, аннотации тональности и другие соответствующие инструменты.

Аннотация изображения
Услуги
Мы гордимся тем, что маркируем сегментированные наборы данных изображений для обучения моделей компьютерного зрения. Некоторые из соответствующих методов включают распознавание границ и классификацию изображений.

Видеоаннотации
Услуги
Shaip предлагает высококачественные услуги по маркировке видео для обучения моделей компьютерного зрения. Цель состоит в том, чтобы сделать наборы данных пригодными для использования с такими инструментами, как распознавание образов, обнаружение объектов и т. Д.


