
Этот метод помогает ИИ знать, когда следует избегать определенных вопросов. Он учится отклонять запросы, содержащие вредоносный контент, например насилие или дискриминацию.
Хорошо известным примером модели, использующей RLHF, является ChatGPT от OpenAI. Эта модель использует обратную связь от людей, чтобы улучшить ответы и сделать их более актуальными и ответственными.
Этапы обучения с подкреплением с обратной связью от человека
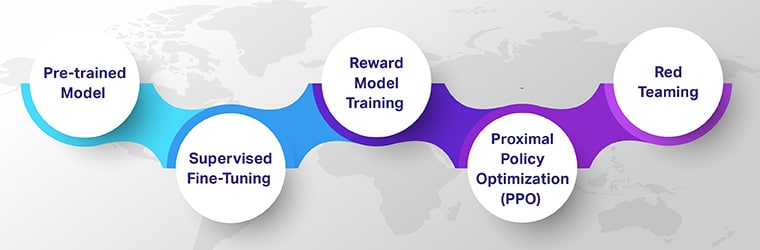
Обучение с подкреплением и обратной связью с человеком (RLHF) гарантирует, что модели ИИ являются технически совершенными, этически обоснованными и контекстуально релевантными. Ознакомьтесь с пятью ключевыми этапами RLHF, которые показывают, как они способствуют созданию сложных систем искусственного интеллекта, управляемых человеком.
Начиная с предварительно обученной модели
Путь RLHF начинается с предварительно обученной модели, что является основополагающим шагом в машинном обучении «человек в цикле». Первоначально обученные на обширных наборах данных, эти модели обладают широким пониманием языка или других основных задач, но не имеют специализации.
Разработчики начинают с предварительно обученной модели и получают значительное преимущество. Эти модели уже изучены на основе огромных объемов данных. Это помогает им сэкономить время и ресурсы на начальном этапе обучения. Этот шаг создает основу для последующего более целенаправленного и конкретного обучения.
Контролируемая тонкая настройка
Второй шаг включает в себя контролируемую тонкую настройку, при которой предварительно обученная модель проходит дополнительное обучение для конкретной задачи или области. Этот шаг характеризуется использованием помеченных данных, что помогает модели генерировать более точные и контекстуально релевантные выходные данные.
Этот процесс тонкой настройки является ярким примером обучения ИИ под руководством человека, где человеческое суждение играет важную роль в направлении ИИ к желаемому поведению и реакциям. Тренеры должны тщательно отбирать и представлять данные, специфичные для предметной области, чтобы гарантировать, что ИИ адаптируется к нюансам и конкретным требованиям поставленной задачи.
Обучение модели вознаграждения
На третьем этапе вы обучаете отдельную модель распознавать и вознаграждать желаемые результаты, которые генерирует ИИ. Этот шаг является центральным в обучении ИИ на основе обратной связи.
Модель вознаграждения оценивает результаты работы ИИ. Он присваивает оценки на основе таких критериев, как релевантность, точность и соответствие желаемым результатам. Эти оценки действуют как обратная связь и направляют ИИ к получению более качественных ответов. Этот процесс позволяет более детально понять сложные или субъективные задачи, когда четких инструкций может быть недостаточно для эффективного обучения.
Обучение с подкреплением посредством оптимизации проксимальной политики (PPO)
Затем ИИ подвергается обучению с подкреплением посредством оптимизации проксимальной политики (PPO), сложного алгоритмического подхода в интерактивном машинном обучении.
PPO позволяет ИИ учиться на основе прямого взаимодействия с окружающей средой. Оно совершенствует процесс принятия решений посредством поощрений и наказаний. Этот метод особенно эффективен при обучении и адаптации в реальном времени, поскольку помогает ИИ понимать последствия своих действий в различных сценариях.
PPO помогает научить ИИ ориентироваться в сложных, динамичных средах, где желаемые результаты могут меняться или их трудно определить.
Красная команда
Последний шаг предполагает тщательное тестирование системы искусственного интеллекта в реальных условиях. Здесь разнообразная группа оценщиков, известная как «красная команда», бросьте вызов ИИ, используя различные сценарии. Они проверяют его способность реагировать точно и адекватно. Этот этап гарантирует, что ИИ сможет справиться с реальными приложениями и непредсказуемыми ситуациями.
Red Teaming проверяет техническую компетентность ИИ, а также этическую и контекстуальную обоснованность. Они гарантируют, что оно действует в рамках приемлемых моральных и культурных границ.
На всех этих этапах RLHF подчеркивает важность участия человека на каждом этапе разработки ИИ. От руководства начальным обучением с использованием тщательно отобранных данных до предоставления подробной обратной связи и тщательного тестирования в реальных условиях — человеческий вклад является неотъемлемой частью создания интеллектуальных, ответственных и отвечающих человеческим ценностям и этике систем ИИ.
Заключение
Обучение с подкреплением и обратной связью с человеком (RLHF) демонстрирует новую эру в области искусственного интеллекта, поскольку оно объединяет человеческие знания с машинным обучением для создания более этичных и точных систем искусственного интеллекта.
RLHF обещает сделать ИИ более чутким, инклюзивным и инновационным. Это может устранить предубеждения и улучшить процесс решения проблем. Он призван преобразовать такие области, как здравоохранение, образование и обслуживание клиентов.
Однако совершенствование этого подхода требует постоянных усилий по обеспечению эффективности, справедливости и этического соответствия.


