



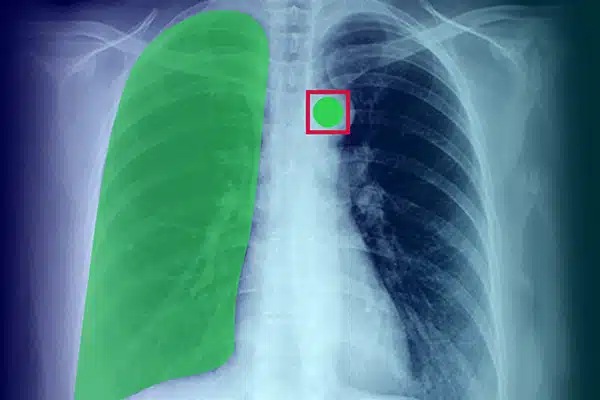
Аннотация изображения
Усовершенствуйте медицинский ИИ, комментируя визуальные данные рентгеновских снимков, компьютерной томографии и МРТ. Убедитесь, что модели искусственного интеллекта превосходно работают в диагностике и лечении, руководствуясь экспертной маркировкой данных. Получите лучшие результаты лечения пациентов благодаря превосходным данным визуализации.
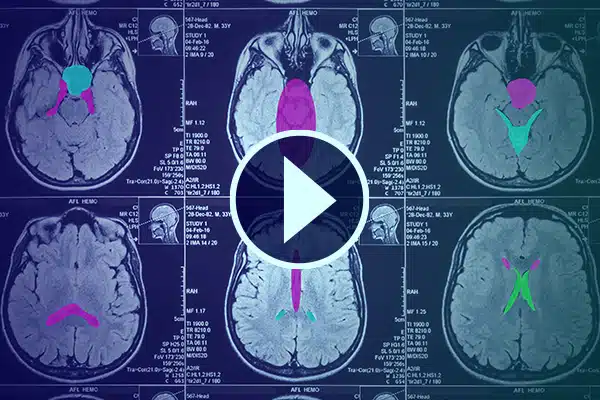
Видеоаннотации
Продвигайте искусственный интеллект в здравоохранении с подробными видеоаннотациями. Усовершенствуйте обучение ИИ с помощью классификаций и сегментации медицинских кадров. Улучшите хирургический искусственный интеллект и мониторинг пациентов, чтобы улучшить оказание медицинских услуг и диагностику.
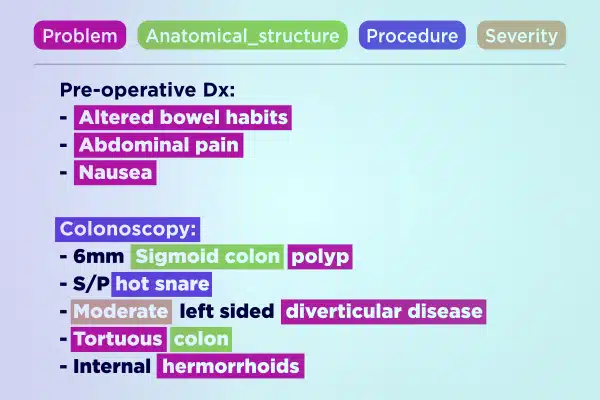
Текстовая аннотация
Оптимизируйте разработку медицинского ИИ с помощью профессионально аннотированных текстовых данных. Быстро анализируйте и обогащайте огромные объемы текста — от рукописных заметок до страховых отчетов. Обеспечьте точную и полезную информацию для развития здравоохранения.

Аудио аннотация
Используйте опыт НЛП для точного аннотирования и маркировки медицинских аудиоданных. Создавайте голосовые системы для бесперебойной клинической работы и интегрируйте искусственный интеллект в различные продукты здравоохранения с голосовым управлением. Повысьте точность диагностики с помощью экспертной обработки аудиоданных.

Медицинское Кодирование
Оптимизируйте медицинскую документацию, преобразовав ее в универсальные коды с помощью медицинского кодирования ИИ. Обеспечьте точность, повысьте эффективность выставления счетов и поддержите бесперебойное предоставление медицинских услуг с помощью передового искусственного интеллекта в кодировании медицинских записей.

Фаза 1: Технический опыт предметной области (понимание области применения и рекомендаций по аннотациям)

Фаза 2: Подготовка соответствующих ресурсов для проекта

Фаза 3: Цикл обратной связи и контроль качества аннотированных документов
Радиология
Наша служба аннотаций радиологических изображений улучшает диагностику с помощью искусственного интеллекта и включает в себя дополнительный уровень знаний. Каждый рентгеновский снимок, МРТ и КТ тщательно маркируется и проверяется экспертом в данной области. Этот дополнительный шаг в обучении и проверке повышает способность ИИ выявлять отклонения и заболевания. Это повышает точность перед доставкой нашим клиентам.

Кардиология
Наши аннотации изображений, ориентированные на кардиологию, улучшают диагностику с помощью искусственного интеллекта. Мы привлекаем экспертов-кардиологов, которые маркируют сложные изображения, связанные с сердцем, и обучают наши модели искусственного интеллекта. Прежде чем мы отправим данные клиентам, эти специалисты проверяют каждое изображение, чтобы обеспечить высочайшую точность. Этот процесс позволяет ИИ более точно выявлять заболевания сердца.
ДЕНТИСТРИЯ
Наша служба аннотаций изображений в стоматологии маркирует стоматологические изображения для улучшения диагностических инструментов искусственного интеллекта. Точно выявляя кариес, проблемы с выравниванием зубов и другие стоматологические заболевания, наши предприятия малого и среднего бизнеса позволяют искусственному интеллекту улучшать результаты лечения пациентов и помогать стоматологам в точном планировании лечения и раннем выявлении.


















Люди
Выделенные и обученные команды:
- Более 30,000 сотрудников по созданию, маркировке и контролю качества данных
- Аттестованная команда управления проектами
- Опытная команда по разработке продуктов
- Команда поиска и адаптации кадрового резерва

Обработка
Наивысшая эффективность процесса обеспечивается:
- Надежный 6-сигма-технологический процесс
- Специальная команда «черных поясов 6 сигм» - владельцы ключевых процессов и соблюдение требований к качеству
- Непрерывное совершенствование и обратная связь

Платформа
Запатентованная платформа предлагает преимущества:
- Сквозная веб-платформа
- Безупречное качество
- Быстрее ТАТ
- Бесшовная доставка



