
Подсчитано, что в среднем взрослый принимает решения о жизни и повседневных вещах на основе прошлого обучения. Они, в свою очередь, исходят из жизненного опыта, сформированного ситуациями и людьми. В буквальном смысле ситуации, случаи и люди - это не что иное, как данные, которые попадают в наш мозг. По мере того как мы накапливаем данные за годы в виде опыта, человеческий разум склонен принимать беспроблемные решения.
Что это передает? Эти данные неизбежны при обучении.
Подобно тому, как ребенку нужна метка, называемая алфавитом, чтобы понимать буквы A, B, C, D, машине также необходимо понимать данные, которые она получает.
Это именно то, что Искусственный интеллект (AI) обучение - это все. Машина ничем не отличается от ребенка, которому еще предстоит изучить то, чему его собираются научить. Машина не умеет различать кошку и собаку, автобус и машину, потому что они еще не испытали эти предметы и не узнали, как они выглядят.
Итак, для тех, кто строит автомобиль с автоматическим управлением, основная функция, которую необходимо добавить, - это способность системы понимать все повседневные элементы, с которыми может столкнуться автомобиль, чтобы автомобиль мог их идентифицировать и принимать соответствующие решения при вождении. Это где Данные обучения ИИ вступает в игру.
Сегодня модули искусственного интеллекта предлагают нам множество удобств в виде механизмов рекомендаций, навигации, автоматизации и многого другого. Все это происходит из-за обучения данных ИИ, которое использовалось для обучения алгоритмов при их создании.
Данные обучения искусственного интеллекта - фундаментальный процесс в создании обучение с помощью машины и алгоритмы ИИ. Если вы разрабатываете приложение, основанное на этих технических концепциях, вам необходимо обучить свои системы пониманию элементов данных для оптимизации обработки. Без обучения ваша модель ИИ будет неэффективной, ошибочной и потенциально бессмысленной.
Что такое данные обучения ИИ?
Данные обучения ИИ — это тщательно отобранная и очищенная информация, которая подается в систему для целей обучения. Этот процесс создает или разрушает успех модели ИИ. Это может помочь в развитии понимания того, что не все четвероногие животные на изображении являются собаками, или может помочь модели отличить гневный крик от радостного смеха. Это первый этап в создании модулей искусственного интеллекта, которые требуют подачи данных с ложки, чтобы научить машины основам и дать им возможность учиться по мере поступления новых данных. Это, опять же, освобождает место для эффективного модуля, который выдает конечным пользователям точные результаты.

Рассматривайте процесс обучения данных ИИ как тренировку для музыканта, где чем больше он практикуется, тем лучше он справляется с песней или гаммой. Единственная разница здесь в том, что машины тоже сначала нужно научить, что такое музыкальный инструмент. Подобно музыканту, который эффективно использует бесчисленные часы, потраченные на репетиции на сцене, модель ИИ предлагает потребителям оптимальный опыт при развертывании.

Какие типы данных мне нужны?
Для эффективного обучения моделей машинного обучения потребуются 4 основных типа данных: изображение, видео, аудио / речь или текст. Тип необходимых данных будет зависеть от множества факторов, таких как конкретный вариант использования, сложность обучаемых моделей, используемый метод обучения и разнообразие требуемых входных данных.
Насколько адекватно данных?
Они говорят, что обучению нет конца, и эта фраза идеально подходит для спектра данных обучения ИИ. Чем больше данных, тем лучше результаты. Однако столь расплывчатого ответа недостаточно, чтобы убедить любого, кто хочет запустить приложение на базе искусственного интеллекта. Но реальность такова, что не существует общего практического правила, формулы, индекса или измерения точного объема данных, необходимых для обучения их наборов данных ИИ.

Эксперт по машинному обучению в шутку сказал бы, что нужно создать отдельный алгоритм или модуль, чтобы вывести объем данных, необходимых для проекта. К сожалению, это тоже реальность.
Теперь есть причина, по которой чрезвычайно сложно ограничить объем данных, необходимых для обучения ИИ. Это связано со сложностями самого тренировочного процесса. Модуль AI состоит из нескольких уровней взаимосвязанных и перекрывающихся фрагментов, которые влияют на процессы друг друга и дополняют их.
Например, предположим, что вы разрабатываете простое приложение для распознавания кокосовой пальмы. Со стороны это звучит довольно просто, правда? Однако с точки зрения ИИ все намного сложнее.
В самом начале машина пуста. Он не знает, что такое дерево в первую очередь, не говоря уже о высоком тропическом плодоносящем дереве, характерном для конкретного региона. Для этого модель должна быть обучена тому, что такое дерево, как отличаться от других высоких и тонких объектов, которые могут появляться в кадре, таких как уличные фонари или электрические столбы, а затем двигаться дальше, чтобы научить ее нюансам кокосовой пальмы. Как только модуль машинного обучения узнает, что такое кокосовая пальма, можно с уверенностью предположить, что он знает, как ее распознать.
Но только когда вы загрузите изображение баньянового дерева, вы поймете, что система ошибочно определила баньяновое дерево за кокосовую пальму. Для системы все, что высокое, с гроздьями листвы, является кокосовой пальмой. Чтобы устранить это, система должна теперь понимать каждое дерево, не являющееся кокосовой пальмой, чтобы точно идентифицировать. Если это процесс для простого однонаправленного приложения с одним результатом, мы можем только представить себе сложности, связанные с приложениями, разработанными для здравоохранения, финансов и многого другого.



Как улучшить качество данных?
Качество данных прямо пропорционально качеству вывода. Вот почему высокоточные модели требуют для обучения высококачественных наборов данных. Однако здесь есть одна загвоздка. Для концепции, основанной на точности и аккуратности, понятие качества часто бывает довольно расплывчатым.
Высококачественные данные звучат убедительно и достоверно, но что это на самом деле означает?
Что такое качество в первую очередь?
Что ж, как и сами данные, которые мы вводим в наши системы, с качеством также связано множество факторов и параметров. Если вы обратитесь к экспертам по искусственному интеллекту или ветеранам машинного обучения, они могут поделиться любыми перестановками высококачественных данных - чем угодно -

- Единая - данные, полученные из одного конкретного источника, или единообразие наборов данных, полученных из нескольких источников.
- Всесторонний - данные, охватывающие все возможные сценарии работы вашей системы
- Последовательный - каждый байт данных похож по своей природе
- Соответствующий - данные, которые вы получаете и кормите, соответствуют вашим требованиям и ожидаемым результатам, а также
- Несколько - у вас есть комбинация всех типов данных, таких как аудио, видео, изображения, текст и т. Д.
Теперь, когда мы понимаем, что означает качество данных, давайте быстро рассмотрим различные способы обеспечения качества. сбор данных и поколение.
Что влияет на качество обучающих данных?
Есть три основных фактора, которые могут помочь вам предсказать желаемый уровень качества для ваших моделей AI / ML. Три ключевых фактора - это люди, процесс и платформа, которые могут создать или сломать ваш проект ИИ.
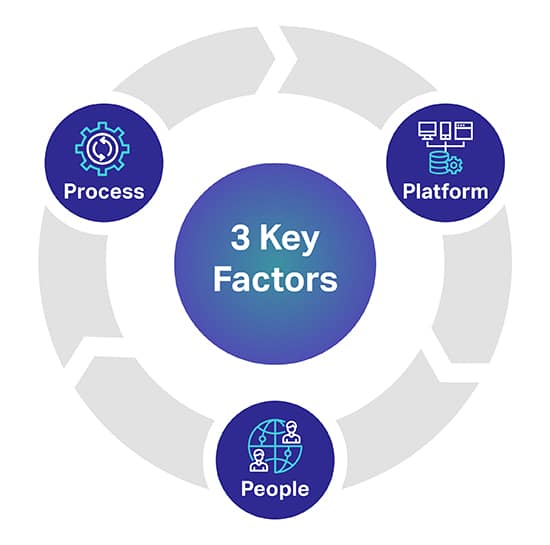
Платформа: Для создания, расшифровки и аннотирования различных наборов данных для успешного развертывания наиболее требовательных инициатив в области искусственного интеллекта и машинного обучения требуется полноценная проприетарная платформа с участием человека в цикле. Платформа также отвечает за управление сотрудниками и максимальное качество и пропускную способность.
Люди: Чтобы заставить ИИ мыслить умнее, нужны люди, которые являются одними из самых умных умов в отрасли. Для масштабирования вам понадобятся тысячи этих профессионалов по всему миру, чтобы транскрибировать, маркировать и аннотировать все типы данных.
Процесс: Получение согласованных, полных и точных данных золотого стандарта - сложная работа. Но это то, что вам всегда нужно будет поставлять, чтобы соответствовать высочайшим стандартам качества, а также строгим и проверенным проверкам качества и контрольно-пропускным пунктам.
Откуда вы получаете данные об обучении ИИ?
В отличие от нашего предыдущего раздела, здесь у нас есть очень точное понимание. Для тех из вас, кто ищет исходные данные
или если вы находитесь в процессе сбора видео, изображений, текста и т. д., есть три
основные возможности, из которых вы можете получить свои данные.
Давайте изучим их индивидуально.
Бесплатные исходники
Бесплатные источники - это каналы, которые являются невольными хранилищами огромных объемов данных. Это данные, которые просто лежат на поверхности бесплатно. Некоторые из бесплатных ресурсов включают в себя -

- Наборы данных Google, по которым в 250 году было выпущено более 2020 миллионов наборов данных.
- Такие форумы, как Reddit, Quora и другие, являются полезными источниками данных. Кроме того, сообщества специалистов по науке о данных и искусственного интеллекта на этих форумах также могут помочь вам с конкретными наборами данных, когда к вам обратятся.
- Kaggle - еще один бесплатный источник, где вы можете найти ресурсы по машинному обучению помимо бесплатных наборов данных.
- Мы также перечислили бесплатные открытые наборы данных, чтобы вы могли начать обучение своих моделей ИИ.
Хотя эти возможности бесплатны, вы в конечном итоге потратите время и усилия. Данные из бесплатных источников повсюду, и вам придется потратить часы работы на поиск, очистку и настройку их в соответствии с вашими потребностями.
Еще один важный момент, о котором следует помнить, - это то, что некоторые данные из бесплатных источников также нельзя использовать в коммерческих целях. Это требует лицензирование данных.
Открытые наборы данных - использовать или не использовать?
 Открытые наборы данных - это общедоступные наборы данных, которые можно использовать в проектах машинного обучения. Не имеет значения, нужен ли вам набор данных на основе аудио, видео, изображения или текста, есть открытые наборы данных, доступные для всех форм и классов данных.
Открытые наборы данных - это общедоступные наборы данных, которые можно использовать в проектах машинного обучения. Не имеет значения, нужен ли вам набор данных на основе аудио, видео, изображения или текста, есть открытые наборы данных, доступные для всех форм и классов данных.
Например, существует набор данных обзоров продуктов Amazon, который содержит более 142 миллионов отзывов пользователей с 1996 по 2014 год. Для изображений у вас есть отличный ресурс, такой как Google Open Images, где вы можете получать наборы данных из более чем 9 миллионов изображений. У Google также есть крыло под названием Machine Perception, которое предлагает около 2 миллионов аудиоклипов продолжительностью десять секунд.
Несмотря на доступность этих (и других) ресурсов, важным фактором, который часто упускается из виду, являются условия, связанные с их использованием. Они наверняка общедоступны, но между нарушением и добросовестным использованием есть тонкая грань. Каждый ресурс имеет свое состояние, и если вы изучаете эти варианты, мы рекомендуем соблюдать осторожность. Это связано с тем, что под предлогом предпочтения свободных средств вы можете в конечном итоге понести судебные иски и сопутствующие расходы.
Истинная стоимость данных обучения ИИ
Только деньги, которые вы тратите на получение данных или создание данных собственными силами, не являются тем, что вам следует учитывать. Мы должны учитывать линейные элементы, такие как время и усилия, затрачиваемые на разработку систем ИИ и стоят с точки зрения сделки. не может похвалить другого.
Время, затраченное на поиск источников и аннотирование данных
Такие факторы, как география, демография рынка и конкуренция в вашей нише, затрудняют доступность соответствующих наборов данных. Время, затрачиваемое на ручной поиск данных, тратит время на обучение вашей системы искусственного интеллекта. Как только вам удастся получить свои данные, вы еще больше откладываете обучение, тратя время на аннотирование данных, чтобы ваша машина могла понять, что ему подают.
Цена сбора и аннотирования данных
Накладные расходы (внутренние сборщики данных, аннотаторы, обслуживание оборудования, техническая инфраструктура, подписки на инструменты SaaS, разработка собственных приложений) необходимо рассчитывать при получении данных AI.
Стоимость плохих данных
Плохие данные могут стоить команде вашей компании морального духа, вашего конкурентного преимущества и других ощутимых последствий, которые останутся незамеченными. Мы определяем неверные данные как любой набор данных, который является нечистым, необработанным, нерелевантным, устаревшим, неточным или полным орфографических ошибок. Плохие данные могут испортить вашу модель искусственного интеллекта, внося предвзятость и искажая ваши алгоритмы с искаженными результатами.
Управленческие расходы
Все расходы, связанные с администрированием вашей организации или предприятия, материальными и нематериальными активами, составляют управленческие расходы, которые довольно часто являются самыми дорогими.

Что дальше после Data Sourcing?
Когда вы получите набор данных в руки, следующим шагом будет его аннотирование или маркировка. После всех сложных задач у вас остаются чистые необработанные данные. Машина по-прежнему не может понять данные, которые у вас есть, потому что они не аннотированы. Здесь начинается оставшаяся часть настоящего испытания.
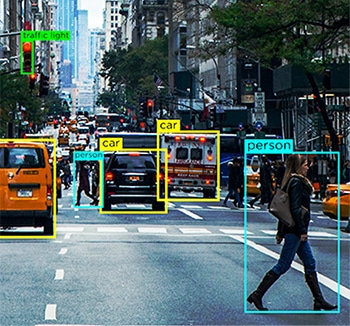
Как мы уже упоминали, машине нужны данные в понятном ей формате. Это именно то, что делает аннотация к данным. Он берет необработанные данные и добавляет слои меток и тегов, чтобы помочь модулю точно понять каждый элемент данных.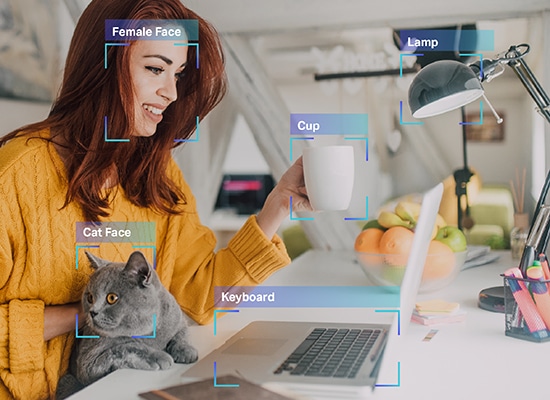
Например, в тексте маркировка данных сообщит системе ИИ грамматический синтаксис, части речи, предлоги, пунктуацию, эмоции, тональность и другие параметры, участвующие в машинном понимании. Таким образом чат-боты лучше понимают человеческие разговоры, и только тогда они могут лучше имитировать человеческие взаимодействия посредством своих ответов.
Как бы неизбежно это ни звучало, это также требует очень много времени и утомительно. Независимо от масштаба вашего бизнеса или его амбиций, время, необходимое для аннотирования данных, огромно.
Это в первую очередь связано с тем, что вашим существующим сотрудникам необходимо выделять время вне своего повседневного графика для аннотирования данных, если у вас нет специалистов по аннотации данных. Итак, вам нужно вызвать членов вашей команды и назначить это как дополнительное задание. Чем больше задержек, тем больше времени потребуется на обучение ваших моделей искусственного интеллекта.
Хотя есть бесплатные инструменты для аннотации данных, это не отменяет того факта, что этот процесс занимает много времени.
Вот тут-то и пригодятся поставщики аннотаций данных, такие как Shaip. Они привлекают специальную команду специалистов по аннотациям данных, чтобы они сосредоточились только на вашем проекте. Они предлагают вам решения в соответствии с вашими потребностями и требованиями. Кроме того, вы можете установить с ними временные рамки и потребовать, чтобы работа была завершена в этот конкретный график.
Одно из основных преимуществ заключается в том, что члены вашей внутренней команды могут продолжать сосредотачиваться на том, что имеет большее значение для вашей деятельности и проекта, в то время как эксперты делают свою работу по аннотированию и маркировке данных за вас.
Благодаря аутсорсингу можно гарантировать оптимальное качество, минимальное время и максимальную точность.