

Что такое большие языковые модели?
Большие языковые модели (LLM) — это передовые системы искусственного интеллекта (ИИ), предназначенные для обработки, понимания и создания текста, подобного человеческому. Они основаны на методах глубокого обучения и обучены на массивных наборах данных, обычно содержащих миллиарды слов из различных источников, таких как веб-сайты, книги и статьи. Это обширное обучение позволяет LLM понимать нюансы языка, грамматики, контекста и даже некоторые аспекты общих знаний.
Некоторые популярные LLM, такие как OpenAI GPT-3, используют тип нейронной сети, называемый преобразователем, который позволяет им решать сложные языковые задачи с замечательным мастерством. Эти модели могут выполнять широкий спектр задач, таких как:
- Отвечая на вопросы
- Обобщающий текст
- Перевод языков
- Генерация контента
- Даже участие в интерактивных беседах с пользователями
Поскольку LLM продолжают развиваться, они обладают большим потенциалом для улучшения и автоматизации различных приложений в разных отраслях, от обслуживания клиентов и создания контента до образования и исследований. Однако они также вызывают этические и социальные проблемы, такие как предвзятое поведение или неправильное использование, которые необходимо решать по мере развития технологий.

Популярные примеры больших языковых моделей
Вот несколько ярких примеров LLM, широко используемых в различных отраслевых вертикалях:
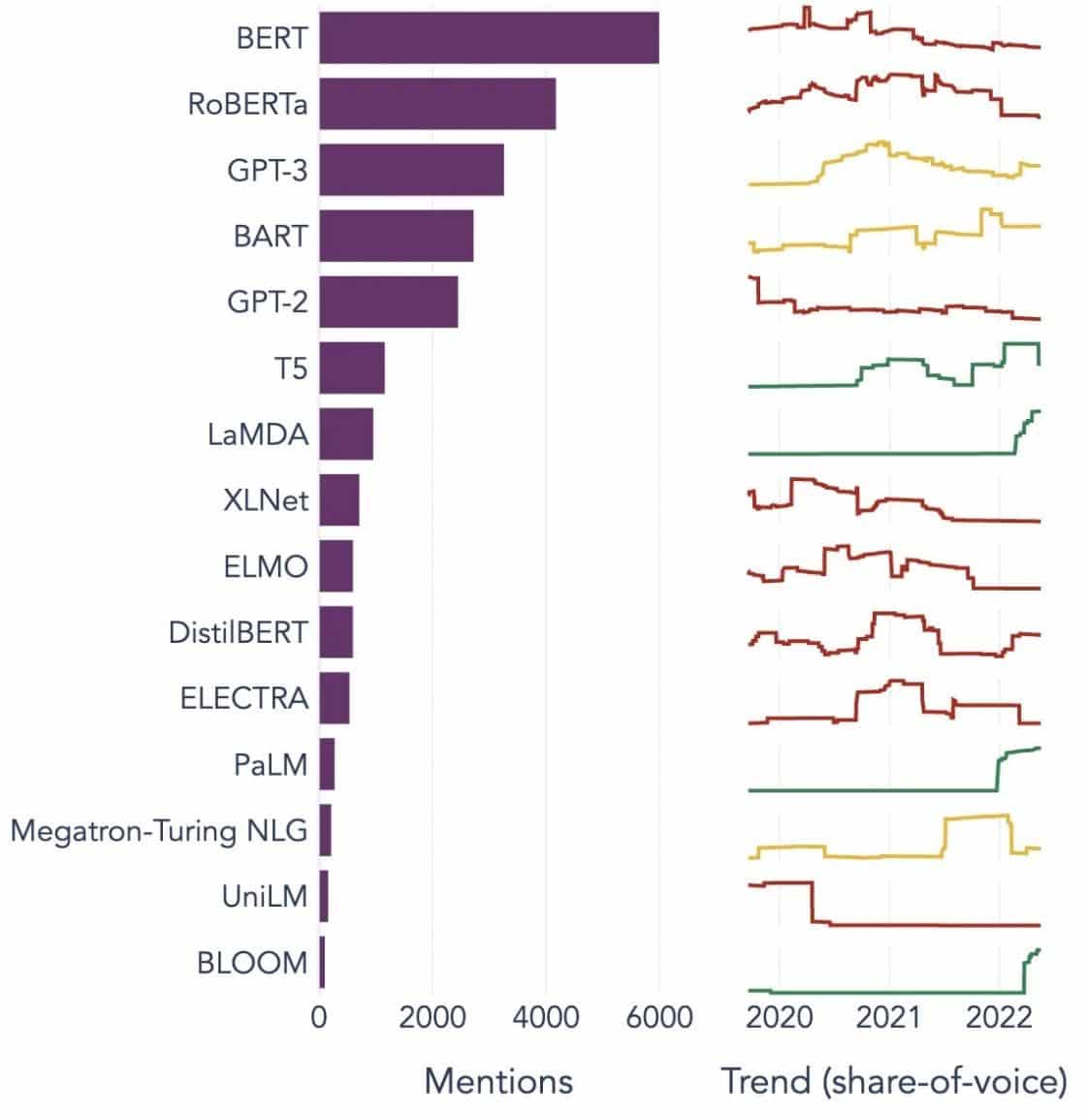
Image Source: На пути к науке о данных
Как модели LLM обучаются?
Обучение больших языковых моделей (LLM) — это настоящий подвиг, который включает в себя несколько важных шагов. Вот упрощенное пошаговое описание процесса:
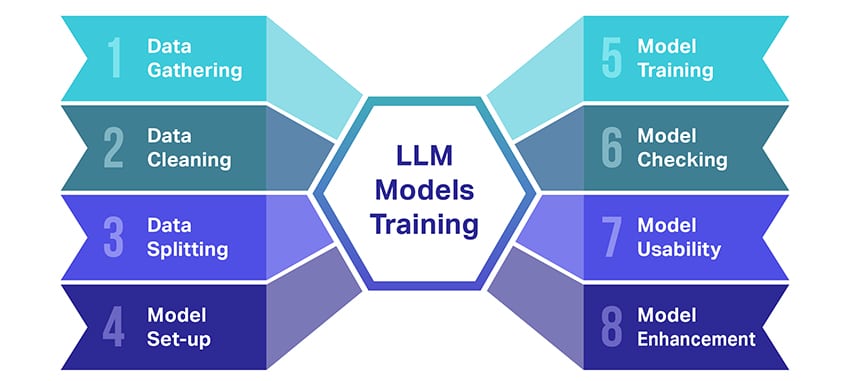
- Сбор текстовых данных: Обучение LLM начинается со сбора большого количества текстовых данных. Эти данные могут поступать из книг, веб-сайтов, статей или платформ социальных сетей. Цель состоит в том, чтобы захватить богатое разнообразие человеческого языка.
- Очистка данных: Затем необработанные текстовые данные упорядочиваются в процессе, называемом предварительной обработкой. Сюда входят такие задачи, как удаление ненужных символов, разбиение текста на более мелкие части, называемые токенами, и преобразование всего этого в формат, с которым может работать модель.
- Разделение данных: Затем чистые данные разбиваются на два набора. Один набор, обучающие данные, будет использоваться для обучения модели. Другой набор, проверочные данные, будет использоваться позже для проверки производительности модели.
- Настройка модели: Затем определяется структура LLM, известная как архитектура. Это включает в себя выбор типа нейронной сети и определение различных параметров, таких как количество слоев и скрытых элементов в сети.
- Обучение модели: Теперь начинается настоящее обучение. Модель LLM учится, просматривая обучающие данные, делая прогнозы на основе того, что она уже узнала, а затем корректируя свои внутренние параметры, чтобы уменьшить разницу между ее прогнозами и фактическими данными.
- Проверка модели: Обучение модели LLM проверяется с использованием проверочных данных. Это помогает увидеть, насколько хорошо работает модель, и настроить параметры модели для повышения производительности.
- Использование модели: После обучения и оценки модель LLM готова к использованию. Теперь его можно интегрировать в приложения или системы, где он будет генерировать текст на основе новых входных данных.
- Улучшение модели: Наконец, всегда есть место для улучшения. Модель LLM можно со временем уточнять, используя обновленные данные или корректируя настройки на основе обратной связи и реального использования.
Помните, что этот процесс требует значительных вычислительных ресурсов, таких как мощные процессоры и большое хранилище, а также специальных знаний в области машинного обучения. Вот почему этим обычно занимаются специализированные исследовательские организации или компании, имеющие доступ к необходимой инфраструктуре и опыту.
Полагается ли LLM на контролируемое или неконтролируемое обучение?
Большие языковые модели обычно обучаются с использованием метода, называемого обучением с учителем. Проще говоря, это означает, что они учатся на примерах, которые показывают им правильные ответы.
 Представьте, что вы учите ребенка словам, показывая ему картинки. Вы показываете им изображение кота и говорите «кошка», и они учатся ассоциировать это изображение со словом. Так работает контролируемое обучение. Модель получает много текста («картинки») и соответствующие выходные данные («слова»), и она учится сопоставлять их.
Представьте, что вы учите ребенка словам, показывая ему картинки. Вы показываете им изображение кота и говорите «кошка», и они учатся ассоциировать это изображение со словом. Так работает контролируемое обучение. Модель получает много текста («картинки») и соответствующие выходные данные («слова»), и она учится сопоставлять их.
Итак, если вы скармливаете LLM предложение, он пытается предсказать следующее слово или фразу на основе того, что он узнал из примеров. Таким образом, он учится генерировать текст, который имеет смысл и соответствует контексту.
Тем не менее, иногда LLM также используют обучение без учителя. Это все равно, что позволить ребенку исследовать комнату, полную разных игрушек, и изучать их самостоятельно. Модель смотрит на немаркированные данные, шаблоны обучения и структуры, не получая при этом «правильных» ответов.
Обучение с учителем использует данные, которые были помечены входными и выходными данными, в отличие от обучения без учителя, которое не использует помеченные выходные данные.
Короче говоря, LLM в основном обучаются с помощью обучения с учителем, но они также могут использовать обучение без учителя для расширения своих возможностей, например, для исследовательского анализа и уменьшения размерности.
Какой объем данных (в ГБ) необходим для обучения большой языковой модели?
Мир возможностей для распознавания речевых данных и голосовых приложений огромен, и они используются в нескольких отраслях для множества приложений.
Обучение большой языковой модели не является универсальным процессом, особенно когда речь идет о необходимых данных. Это зависит от кучи вещей:
- Дизайн модели.
- Какую работу он должен выполнять?
- Тип данных, которые вы используете.
- Насколько хорошо вы хотите, чтобы он работал?
Тем не менее, для обучения LLM обычно требуется огромное количество текстовых данных. Но о какой массе мы говорим? Ну, подумайте не только о гигабайтах (ГБ). Обычно мы рассматриваем терабайты (ТБ) или даже петабайты (ПБ) данных.
Рассмотрим GPT-3, один из крупнейших LLM. Он обучается на 570 ГБ текстовых данных. Меньшим LLM может потребоваться меньше — может быть, 10–20 ГБ или даже 1 ГБ гигабайт, — но это все равно много.

Но дело не только в размере данных. Качество тоже имеет значение. Данные должны быть чистыми и разнообразными, чтобы модель могла эффективно учиться. И вы не можете забыть о других ключевых элементах головоломки, таких как необходимая вычислительная мощность, алгоритмы, которые вы используете для обучения, и настройка вашего оборудования. Все эти факторы играют большую роль в обучении LLM.
Возникновение больших языковых моделей: почему они важны
LLM больше не просто концепция или эксперимент. Они играют все более важную роль в нашем цифровом ландшафте. Но почему это происходит? Что делает эти LLM такими важными? Давайте углубимся в некоторые ключевые факторы.
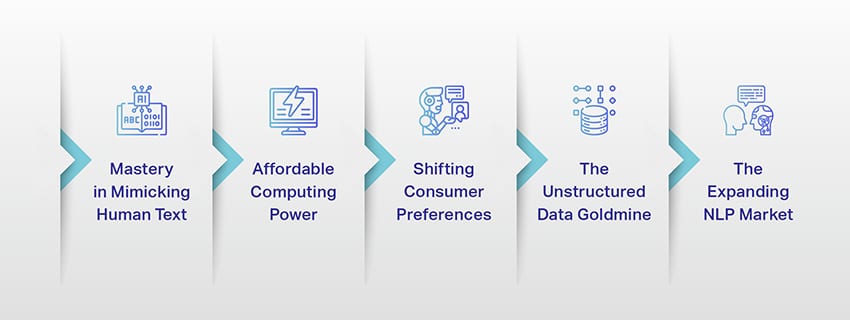
Мастерство имитации человеческого текста
LLM изменили то, как мы справляемся с языковыми задачами. Эти модели, созданные с использованием надежных алгоритмов машинного обучения, способны понимать нюансы человеческого языка, включая контекст, эмоции и даже сарказм в некоторой степени. Эта способность имитировать человеческий язык не просто новинка, она имеет важные последствия.
Расширенные возможности LLM по генерации текста могут улучшить все, от создания контента до взаимодействия со службой поддержки клиентов.
Представьте, что вы можете задать цифровому ассистенту сложный вопрос и получить ответ, который не только имеет смысл, но и связен, актуален и представлен в разговорном тоне. Это то, что позволяют LLM. Они способствуют более интуитивному и увлекательному взаимодействию человека с машиной, обогащают пользовательский опыт и демократизируют доступ к информации.
Доступная вычислительная мощность
Рост LLM был бы невозможен без параллельных разработок в области вычислительной техники. В частности, демократизация вычислительных ресурсов сыграла значительную роль в развитии и внедрении LLM.
Облачные платформы предлагают беспрецедентный доступ к высокопроизводительным вычислительным ресурсам. Таким образом, даже небольшие организации и независимые исследователи могут обучать сложные модели машинного обучения.
Более того, усовершенствования процессоров (таких как GPU и TPU) в сочетании с распространением распределенных вычислений сделали возможным обучение моделей с миллиардами параметров. Эта повышенная доступность вычислительной мощности способствует росту и успеху LLM, что приводит к большему количеству инноваций и приложений в этой области.
Изменение потребительских предпочтений
Сегодня потребители не просто хотят получить ответы; они хотят увлекательных и родственных взаимодействий. Поскольку все больше людей растут с использованием цифровых технологий, становится очевидным, что потребность в технологиях, которые кажутся более естественными и похожими на человека, возрастает. LLM предлагают непревзойденную возможность оправдать эти ожидания. Генерируя человекоподобный текст, эти модели могут создавать увлекательные и динамичные цифровые впечатления, которые могут повысить удовлетворенность и лояльность пользователей. Будь то чат-боты с искусственным интеллектом, обеспечивающие обслуживание клиентов, или голосовые помощники, предоставляющие обновления новостей, LLM открывают эру искусственного интеллекта, который лучше нас понимает.
Золотая жила неструктурированных данных
Неструктурированные данные, такие как электронные письма, сообщения в социальных сетях и отзывы клиентов, являются сокровищницей идей. Подсчитано, что более 80% корпоративных данных неструктурированы и растут со скоростью 55% в год. Эти данные — золотая жила для бизнеса, если их правильно использовать.
Здесь в игру вступают LLM с их способностью обрабатывать и понимать такие данные в масштабе. Они могут выполнять такие задачи, как анализ тональности, классификация текста, извлечение информации и многое другое, тем самым предоставляя ценную информацию.
Будь то выявление тенденций из сообщений в социальных сетях или оценка настроений клиентов по отзывам, LLM помогают предприятиям ориентироваться в большом объеме неструктурированных данных и принимать решения на основе данных.
Расширяющийся рынок НЛП
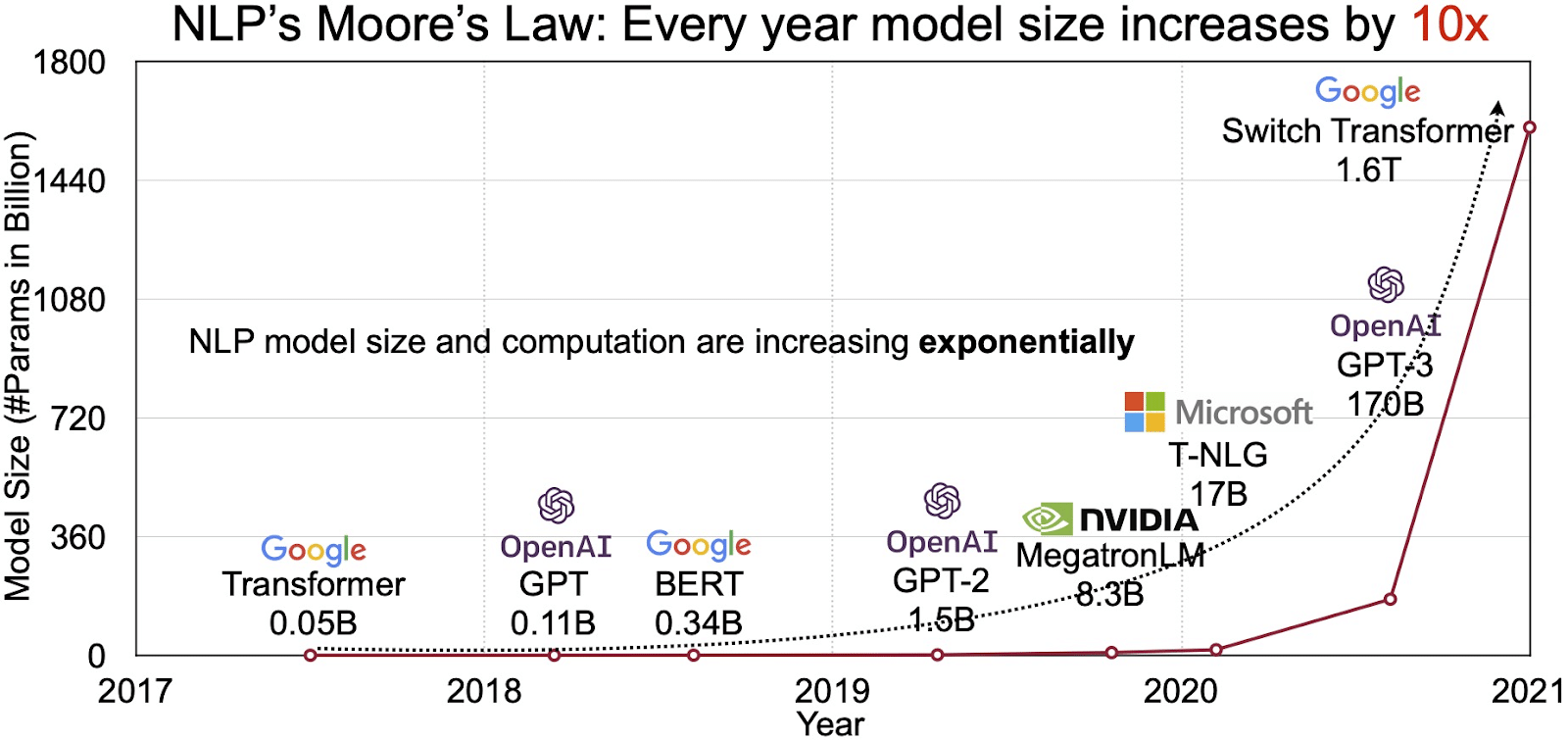
Потенциал LLM отражается в быстро растущем рынке обработки естественного языка (NLP). Аналитики прогнозируют расширение рынка НЛП с 11 миллиардов долларов в 2020 году до более чем 35 миллиардов долларов к 2026 году. Но расширяется не только размер рынка. Сами модели тоже растут, как по физическим размерам, так и по количеству обрабатываемых параметров. Эволюция LLM на протяжении многих лет, как показано на рисунке ниже (источник изображения: ссылка), подчеркивает их растущую сложность и возможности.
Популярные варианты использования больших языковых моделей
Вот некоторые из лучших и наиболее распространенных вариантов использования LLM:
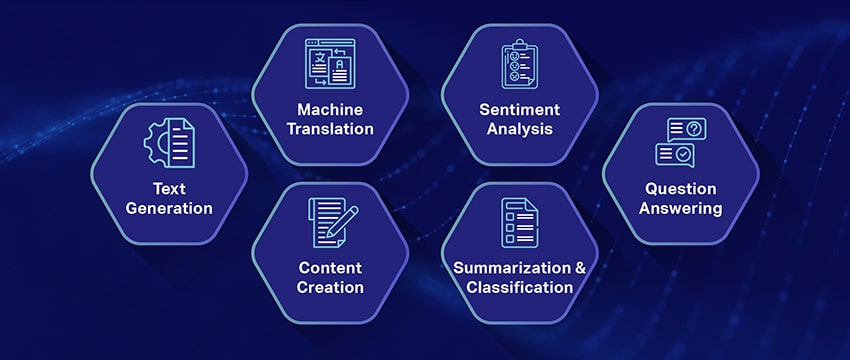
- Создание текста на естественном языке: Модели больших языков (LLM) сочетают в себе возможности искусственного интеллекта и вычислительной лингвистики для автономного создания текстов на естественном языке. Они могут удовлетворить различные потребности пользователей, такие как написание статей, создание песен или участие в беседах с пользователями.
- Перевод через машины: LLM можно эффективно использовать для перевода текста между любой парой языков. Эти модели используют алгоритмы глубокого обучения, такие как рекуррентные нейронные сети, для понимания лингвистической структуры как исходного, так и целевого языков, тем самым облегчая перевод исходного текста на нужный язык.
- Создание оригинального контента: LLM открыли машинам возможности для создания связного и логичного контента. Этот контент можно использовать для создания сообщений в блогах, статей и других типов контента. Модели используют свой глубокий опыт глубокого обучения для форматирования и структурирования контента новым и удобным для пользователя способом.
- Анализ настроений: Одним из интригующих приложений больших языковых моделей является анализ настроений. При этом модель обучается распознавать и классифицировать эмоциональные состояния и чувства, присутствующие в аннотированном тексте. Программное обеспечение может идентифицировать такие эмоции, как позитивность, негативность, нейтральность и другие сложные чувства. Это может дать ценную информацию об отзывах и мнениях клиентов о различных продуктах и услугах.
- Понимание, обобщение и классификация текста: LLM создают жизнеспособную структуру программного обеспечения ИИ для интерпретации текста и его контекста. Поручая модели понимать и анализировать огромные объемы данных, LLM позволяют моделям ИИ понимать, обобщать и даже классифицировать текст в различных формах и шаблонах.
- Отвечая на вопросы: Модели большого языка предоставляют системам QA возможность точно воспринимать запросы пользователя на естественном языке и отвечать на них. Популярные примеры этого варианта использования включают ChatGPT и BERT, которые изучают контекст запроса и просеивают обширную коллекцию текстов, чтобы предоставить соответствующие ответы на вопросы пользователей.

Добавление тегов части речи (POS)
Слова в предложениях помечаются с указанием их грамматической функции, такой как глаголы, существительные, прилагательные и т. д. Этот процесс помогает модели понять грамматику и связи между словами.

Распознавание именованных сущностей (NER)
Именованные объекты, такие как организации, места и люди в предложении, помечаются. Это упражнение помогает модели интерпретировать семантическое значение слов и фраз и дает более точные ответы.

Анализ настроений
Текстовым данным назначаются метки настроений, такие как положительное, нейтральное или отрицательное, что помогает модели понять эмоциональный оттенок предложений. Это особенно полезно при ответах на вопросы, связанные с эмоциями и мнениями.
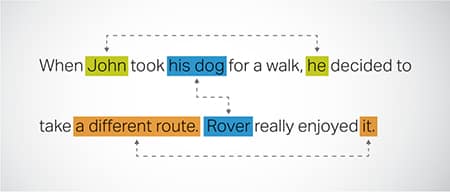
Разрешение Coreference
Выявление и разрешение случаев, когда один и тот же объект упоминается в разных частях текста. Этот шаг помогает модели понять контекст предложения, что приводит к связным ответам.
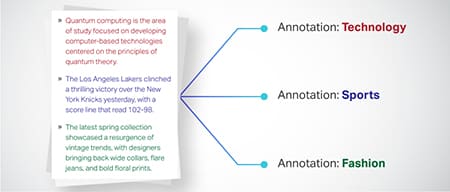
Классификация текста
Текстовые данные классифицируются по предопределенным группам, таким как обзоры продуктов или новостные статьи. Это помогает модели различать жанр или тему текста, генерируя более подходящие ответы.
Предложение Шаипа
Шаип предлагает широкий спектр услуг, помогающих организациям управлять, анализировать и максимально эффективно использовать свои данные.
Веб-скрейпинг данных
Одной из ключевых услуг, предлагаемых Shaip, является очистка данных. Это включает в себя извлечение данных из URL-адресов, специфичных для домена. Используя автоматизированные инструменты и методы, Shaip может быстро и эффективно собирать большие объемы данных с различных веб-сайтов, руководств по продуктам, технической документации, онлайн-форумов, онлайн-обзоров, данных обслуживания клиентов, отраслевых нормативных документов и т. д. Этот процесс может быть бесценным для предприятий, когда сбор релевантных и конкретных данных из множества источников.

Машинный перевод
Разрабатывайте модели, используя обширные многоязычные наборы данных в сочетании с соответствующими транскрипциями для перевода текста на разные языки. Этот процесс помогает устранить языковые препятствия и способствует доступности информации.
Извлечение и создание таксономии
Shaip может помочь с извлечением и созданием таксономии. Это включает в себя классификацию и категоризацию данных в структурированном формате, отражающем отношения между различными точками данных. Это может быть особенно полезно для предприятий при организации своих данных, делая их более доступными и удобными для анализа. Например, в сфере электронной коммерции данные о продуктах могут быть классифицированы по типу продукта, бренду, цене и т. д., что упрощает для клиентов навигацию по каталогу продуктов.
Сбор данных
Наши услуги по сбору данных предоставляют важные реальные или синтетические данные, необходимые для обучения алгоритмов генеративного ИИ и повышения точности и эффективности ваших моделей. Данные беспристрастны, этичны и ответственны, с учетом конфиденциальности и безопасности данных.

Вопрос и ответ
Ответы на вопросы (QA) — это область обработки естественного языка, ориентированная на автоматические ответы на вопросы на человеческом языке. Системы контроля качества обучаются на обширном тексте и коде, что позволяет им обрабатывать различные типы вопросов, включая фактические, определяющие и основанные на мнениях. Знание предметной области имеет решающее значение для разработки моделей контроля качества, адаптированных к конкретным областям, таким как поддержка клиентов, здравоохранение или цепочка поставок. Однако подходы генеративного контроля качества позволяют моделям генерировать текст без знания предметной области, полагаясь исключительно на контекст.
Наша команда специалистов может тщательно изучить исчерпывающие документы или руководства для создания пар «вопрос-ответ», облегчая создание генеративного ИИ для бизнеса. Этот подход может эффективно решать запросы пользователей, извлекая соответствующую информацию из обширного корпуса. Наши сертифицированные эксперты обеспечивают создание высококачественных пар вопросов и ответов, которые охватывают различные темы и области.

Обобщение текста
Наши специалисты способны упорядочить всесторонние разговоры или длинные диалоги, представляя краткие и содержательные резюме из обширных текстовых данных.

Генерация текста
Обучайте модели, используя широкий набор данных текста в различных стилях, таких как новостные статьи, художественная литература и поэзия. Затем эти модели могут генерировать различные типы контента, включая новости, записи в блогах или сообщения в социальных сетях, предлагая экономичное и экономящее время решение для создания контента.
Распознавание речи
Разрабатывайте модели, способные понимать разговорный язык для различных приложений. Сюда входят голосовые помощники, программное обеспечение для диктовки и инструменты перевода в реальном времени. Процесс включает в себя использование всеобъемлющего набора данных, состоящего из аудиозаписей разговорной речи в сочетании с соответствующими расшифровками.

Рекомендации по продукту
Разрабатывайте модели, используя обширные наборы данных об историях покупок клиентов, включая этикетки, указывающие на продукты, которые клиенты склонны покупать. Цель состоит в том, чтобы предоставить точные предложения клиентам, тем самым увеличивая продажи и повышая удовлетворенность клиентов.
Подписи к изображениям
Измените свой процесс интерпретации изображений с помощью нашего современного сервиса подписей к изображениям на основе искусственного интеллекта. Мы наполняем изображения жизненной силой, создавая точные и контекстуально значимые описания. Это прокладывает путь к инновационным возможностям взаимодействия и взаимодействия с вашим визуальным контентом для вашей аудитории.

Обучение работе с преобразованием текста в речь
Мы предоставляем обширный набор данных, состоящий из аудиозаписей человеческой речи, идеально подходящих для обучения моделей ИИ. Эти модели способны генерировать естественные и привлекательные голоса для ваших приложений, обеспечивая тем самым отличительный и захватывающий звук для ваших пользователей.



