
Ключ к преодолению препятствий развитию ИИ: более надежные данные
Сегодня у среднего человека в кармане в миллионы раз больше вычислительной мощности, чем было у НАСА для высадки на Луну в 1969 году. То же самое повсеместное устройство, которое удобно демонстрирует изобилие вычислительной мощности, также выполняет еще одно условие для золотого века ИИ: обилие данных. Согласно данным исследовательской группы Information Overload Research Group, 90% мировых данных было создано за последние два года. Теперь, когда экспоненциальный рост вычислительной мощности, наконец, соединился с столь же стремительным ростом генерации данных, инновации в области данных ИИ стремительно набирают силу, что, по мнению некоторых экспертов, станет толчком для четвертой промышленной революции.
Данные Национальной ассоциации венчурного капитала показывают, что в первом квартале 6.9 года в сектор ИИ были вложены рекордные 2020 млрд долларов США. Нетрудно увидеть потенциал инструментов ИИ, потому что он уже используется повсюду вокруг нас. Некоторые из наиболее очевидных вариантов использования продуктов AI - это механизмы рекомендаций, стоящие за нашими любимыми приложениями, такими как Spotify и Netflix. Хотя интересно найти нового артиста, которого можно послушать, или новое телешоу, которое можно перекусить, эти реализации довольно низки. Другие алгоритмы оценивают результаты тестов - частично определяя, куда студенты принимаются в колледж, - а третьи просеивают резюме кандидатов, решая, какие кандидаты получат конкретную работу. Некоторые инструменты искусственного интеллекта могут даже иметь последствия для жизни или смерти, например, модель искусственного интеллекта, которая проверяет наличие рака груди (которая превосходит врачей).
Несмотря на устойчивый рост как реальных примеров разработки ИИ, так и количества стартапов, соперничающих за создание нового поколения трансформационных инструментов, проблемы на пути к эффективной разработке и внедрению остаются. В частности, выходной сигнал AI настолько точен, насколько позволяет входной сигнал, а это означает, что качество имеет первостепенное значение.

Навигация по сложным требованиям соответствия
Как будто найти качественные данные было недостаточно сложно, некоторые из отраслей, которые могут получить максимальную выгоду от инноваций в области данных ИИ, также являются наиболее жестко регулируемыми. Здравоохранение, пожалуй, лучший пример, и хотя опрос, проведенный HIT Infrastructure, показал, что 91% инсайдеров отрасли считают, что технология может улучшить доступ к медицинской помощи, этот оптимизм сдерживается тем фактом, что 75% видят в ней угрозу безопасности и конфиденциальности пациентов. - и риску подвергаются не только пациенты.
Широкие нормативные акты, введенные в действие Законом о переносимости и подотчетности в медицинском страховании, в настоящее время пересекаются с различными препятствиями, связанными с соблюдением требований местных данных, такими как Общие правила защиты данных в Европе, Закон о конфиденциальности потребителей Калифорнии в США и Закон о защите личных данных в Сингапуре. К этим местным нормативным актам будет добавлено гораздо больше, и по мере того, как телездравоохранение становится все более важным источником данных о здравоохранении, вполне вероятно, что нормативные акты станут еще жестче контролировать данные о пациентах в пути. В результате безопасная и совместимая облачная платформа Shaip окажется еще более ценным средством сбора и доступа к медицинским данным для обучения продуктов искусственного интеллекта.
Информация, позволяющая установить личность, может стать серьезной угрозой для вашего развития ИИ, но даже полностью соответствующая реализация находится под угрозой, если она не может предоставить точные результаты, которые приходят только с различными данными обучения. Исследование 2020 года, опубликованное в Журнале Американской медицинской ассоциации, показало, что алгоритмы машинного обучения в области медицины чаще всего обучаются на данных пациентов из Калифорнии, Нью-Йорка и Массачусетса. Учитывая, что эти пациенты составляют менее одной пятой населения США, не говоря уже об остальном мире, трудно представить, как эти модели могут давать что-либо, кроме предвзятых результатов.

 Признавая сложность получения совместимой, географически разнообразной информации, Shaip предлагает лицензированные медицинские данные из самых разных регионов, специально отобранных с целью создания точных алгоритмов. Эти данные поступают в виде текста, такого как медицинские записи или информация о претензиях, медицинской диагностической визуализации, такой как компьютерная томография, аудио, например устных заметок врачей или бесед между врачами и пациентами, и даже видео с результатами МРТ. Он также полностью деидентифицирован и анонимен, защищая вашу организацию как от этических, так и от финансовых последствий, которые могут последовать за нарушением любого из растущего числа нормативных актов, регулирующих данные как внутреннего, так и международного происхождения.
Признавая сложность получения совместимой, географически разнообразной информации, Shaip предлагает лицензированные медицинские данные из самых разных регионов, специально отобранных с целью создания точных алгоритмов. Эти данные поступают в виде текста, такого как медицинские записи или информация о претензиях, медицинской диагностической визуализации, такой как компьютерная томография, аудио, например устных заметок врачей или бесед между врачами и пациентами, и даже видео с результатами МРТ. Он также полностью деидентифицирован и анонимен, защищая вашу организацию как от этических, так и от финансовых последствий, которые могут последовать за нарушением любого из растущего числа нормативных актов, регулирующих данные как внутреннего, так и международного происхождения.
Преодоление препятствий развитию ИИ
Усилия по разработке ИИ включают значительные препятствия, независимо от того, в какой отрасли они работают, и процесс перехода от осуществимой идеи к успешному продукту сопряжен с трудностями. Между проблемами получения нужных данных и необходимостью их анонимности для соблюдения всех соответствующих правил может показаться, что создание и обучение алгоритма - это самая простая часть.
Чтобы дать вашей организации все преимущества, необходимые для разработки революционной новой разработки ИИ, вам следует рассмотреть возможность партнерства с такой компанией, как Shaip. Четан Парих и Ватсал Гия основали Shaip, чтобы помогать компаниям разрабатывать решения, которые могут преобразовать здравоохранение в США. За более чем 16 лет работы наша компания выросла и насчитывает более 600 членов команды, и мы работали с сотнями клиентов, чтобы превратить убедительные идеи в решения на основе искусственного интеллекта.
Благодаря нашим сотрудникам, процессам и платформе, работающим на вашу организацию, вы можете сразу получить следующие четыре преимущества и катапультировать свой проект к успешному завершению:
1. Способность освободить ваших специалистов по данным
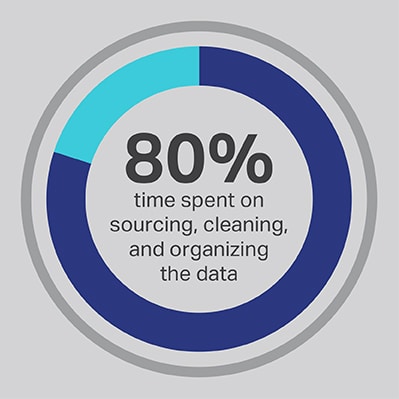
Нельзя избежать того, что процесс разработки ИИ требует значительных затрат времени, но вы всегда можете оптимизировать функции, на выполнение которых ваша команда тратит больше всего времени. Вы наняли своих специалистов по данным, потому что они являются экспертами в разработке передовых алгоритмов и моделей машинного обучения, но исследования последовательно демонстрируют, что эти сотрудники фактически тратят 80% своего времени на поиск, очистку и организацию данных, которые будут использоваться в проекте. Более трех четвертей (76%) специалистов по обработке данных сообщают, что эти рутинные процессы сбора данных также являются их наименее любимой частью работы, но потребность в качественных данных оставляет лишь 20% их времени на фактическую разработку, то есть самая интересная и интеллектуально стимулирующая работа для многих специалистов по данным. Получая данные от стороннего поставщика, такого как Shaip, компания может позволить своим дорогостоящим и талантливым инженерам по обработке данных передать их работу в качестве уборщиков данных и вместо этого тратить свое время на те части решений ИИ, где они могут принести наибольшую пользу.
2. Способность добиваться лучших результатов
 Многие лидеры в области разработки ИИ решают использовать данные из открытых источников или краудсорсинговые данные для сокращения расходов, но это решение почти всегда в конечном итоге обходится дороже. Эти типы данных легко доступны, но они не могут сравниться по качеству с тщательно подобранными наборами данных. В частности, краудсорсинговые данные изобилуют ошибками, упущениями и неточностями, и хотя эти проблемы иногда можно решить в процессе разработки под бдительным взглядом ваших инженеров, требуются дополнительные итерации, которые не потребовались бы, если бы вы начали с более высокого уровня. -качественные данные с самого начала.
Многие лидеры в области разработки ИИ решают использовать данные из открытых источников или краудсорсинговые данные для сокращения расходов, но это решение почти всегда в конечном итоге обходится дороже. Эти типы данных легко доступны, но они не могут сравниться по качеству с тщательно подобранными наборами данных. В частности, краудсорсинговые данные изобилуют ошибками, упущениями и неточностями, и хотя эти проблемы иногда можно решить в процессе разработки под бдительным взглядом ваших инженеров, требуются дополнительные итерации, которые не потребовались бы, если бы вы начали с более высокого уровня. -качественные данные с самого начала.
Опора на данные из открытых источников - еще один распространенный ярлык, который имеет свой собственный набор подводных камней. Отсутствие дифференциации - одна из самых больших проблем, потому что алгоритм, обученный с использованием данных с открытым исходным кодом, легче реплицируется, чем алгоритм, построенный на лицензионных наборах данных. Выбирая этот путь, вы приглашаете конкурентов со стороны других участников рынка, которые могут снизить ваши цены и занять долю рынка в любое время. Когда вы полагаетесь на Shaip, вы получаете доступ к данным высочайшего качества, собранным квалифицированным персоналом, и мы можем предоставить вам эксклюзивную лицензию на настраиваемый набор данных, который не позволяет конкурентам легко воссоздать вашу с трудом завоеванную интеллектуальную собственность.
3. Доступ к опытным профессионалам.
 Даже если в вашем штатном расписании есть опытные инженеры и талантливые специалисты по данным, ваши инструменты искусственного интеллекта могут извлечь выгоду из мудрости, которая приходит только через опыт. Наши отраслевые эксперты выступили инициаторами многочисленных внедрений искусственного интеллекта в своих областях и извлекли ценные уроки на этом пути, и их единственная цель - помочь вам в достижении ваших целей.
Даже если в вашем штатном расписании есть опытные инженеры и талантливые специалисты по данным, ваши инструменты искусственного интеллекта могут извлечь выгоду из мудрости, которая приходит только через опыт. Наши отраслевые эксперты выступили инициаторами многочисленных внедрений искусственного интеллекта в своих областях и извлекли ценные уроки на этом пути, и их единственная цель - помочь вам в достижении ваших целей.
Благодаря тому, что эксперты в предметной области идентифицируют, систематизируют, классифицируют и маркируют данные для вас, вы знаете, что информация, используемая для обучения вашего алгоритма, может дать наилучшие возможные результаты. Мы также регулярно проводим контроль качества, чтобы убедиться, что данные соответствуют высочайшим стандартам и будут работать должным образом не только в лаборатории, но и в реальных условиях.
4. Ускоренный график разработки
Разработка ИИ не происходит в одночасье, но может произойти быстрее, если вы станете партнером Shaip. Собственный сбор данных и аннотации создают существенное «узкое место» в работе, которое задерживает остальную часть процесса разработки. Работа с Shaip дает вам мгновенный доступ к нашей обширной библиотеке готовых к использованию данных, а наши эксперты смогут получить любые необходимые вам дополнительные данные, используя наши глубокие отраслевые знания и глобальную сеть. Без бремени поиска источников и аннотаций ваша команда может сразу приступить к работе над реальной разработкой, а наша модель обучения может помочь выявить неточности на раннем этапе, чтобы сократить количество итераций, необходимых для достижения целей точности.
Если вы не готовы отдать на аутсорсинг все аспекты управления данными, Shaip также предлагает облачную платформу, которая помогает командам более эффективно создавать, изменять и аннотировать различные типы данных, включая поддержку изображений, видео, текста и аудио. . ShaipCloud включает в себя множество интуитивно понятных инструментов проверки и рабочего процесса, таких как запатентованное решение для отслеживания и мониторинга рабочих нагрузок, инструмент транскрипции для расшифровки сложных и сложных аудиозаписей и компонент контроля качества для обеспечения бескомпромиссного качества. Лучше всего то, что он масштабируемый, поэтому он может расти по мере увеличения различных требований вашего проекта.
Эра инноваций в области искусственного интеллекта только начинается, и в ближайшие годы мы увидим невероятные достижения и инновации, которые могут изменить целые отрасли или даже общество в целом. В Shaip мы хотим использовать наш опыт, чтобы служить преобразующей силой, помогая самым революционным компаниям в мире использовать возможности ИИ-решений для достижения амбициозных целей.
У нас есть большой опыт в области медицинских приложений и разговорного ИИ, но мы также обладаем необходимыми навыками для обучения моделей практически для любых приложений. Для получения дополнительной информации о том, как Shaip может помочь продвинуть ваш проект от идеи до реализации, просмотрите множество ресурсов, доступных на нашем веб-сайте, или свяжитесь с нами сегодня.
