
Автоматическое распознавание речи (ASR) прошло долгий путь. Хотя он был изобретен давно, он почти никогда не использовался. Однако время и технологии сейчас существенно изменились. Аудиотранскрипция претерпела значительные изменения.
Такие технологии, как ИИ (искусственный интеллект), привели в действие процесс преобразования аудио в текст для получения быстрых и точных результатов. В результате его приложения в реальном мире также увеличились, а некоторые популярные приложения, такие как Tik Tok, Spotify и Zoom, встраивают этот процесс в свои мобильные приложения.
Итак, давайте рассмотрим ASR и узнаем, почему это одна из самых популярных технологий в 2022 году.
Что такое речь для текста?
Преобразование речи в текст — это улучшенная технология искусственного интеллекта, которая переводит человеческую речь из аналоговой формы в цифровую. Далее цифровая форма собранных данных транскрибируется в текстовый формат.
Преобразование речи в текст часто путают с распознаванием голоса, которое полностью отличается от этого метода. При распознавании голоса основное внимание уделяется идентификации голосовых моделей людей, тогда как в этом методе система пытается идентифицировать произносимые слова.
Общие названия преобразования речи в текст
Эта передовая технология распознавания речи также популярна и называется по именам:
- Автоматическое распознавание речи (ASR)
- Распознавание речи
- Компьютерное распознавание речи
- Аудио транскрипция
- Чтение экрана
Понимание работы автоматического распознавания речи
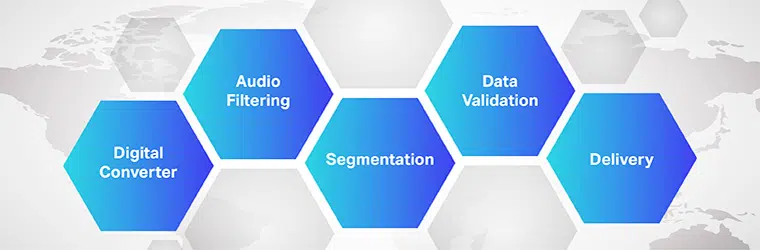
Работа программного обеспечения для перевода аудио в текст сложна и включает в себя выполнение нескольких шагов. Как мы знаем, преобразование речи в текст — это эксклюзивное программное обеспечение, предназначенное для преобразования аудиофайлов в редактируемый текстовый формат; он делает это, используя распознавание голоса.
Обработка
- Первоначально с помощью аналого-цифрового преобразователя компьютерная программа применяет к предоставленным данным лингвистические алгоритмы, чтобы отличать вибрации от звуковых сигналов.
- Затем соответствующие звуки фильтруются путем измерения звуковых волн.
- Кроме того, звуки распределяются/сегментируются на сотые или тысячные доли секунды и сопоставляются с фонемами (измеримой единицей звука, позволяющей отличить одно слово от другого).
- Затем фонемы проходят через математическую модель для сравнения существующих данных с хорошо известными словами, предложениями и фразами.
- Результатом является текстовый или компьютерный аудиофайл.
[Также Читайте: Всесторонний обзор автоматического распознавания речи]

Каковы виды использования речи в текст?
Существует несколько вариантов использования программного обеспечения для автоматического распознавания речи, например
- Поиск контента: Большинство из нас перешли от набора букв на телефонах к нажатию кнопки, чтобы программное обеспечение распознавало наш голос и предоставляло желаемые результаты.
- Обслуживание клиентов: Чат-боты и помощники с искусственным интеллектом, которые могут провести клиентов через несколько начальных шагов процесса, стали обычным явлением.
- Скрытые субтитры в реальном времени: С расширением глобального доступа к контенту скрытые субтитры в режиме реального времени стали заметным и значительным рынком, продвигая ASR вперед для его использования.
- Электронная документация: Несколько административных отделов начали использовать ASR для выполнения задач документирования, обеспечивая более высокую скорость и эффективность.
Каковы основные проблемы распознавания речи?
Аудио аннотация еще не достиг вершины своего развития. Есть еще много проблем, которые инженеры пытаются решить, чтобы сделать систему эффективной, например:
- Получение контроля над акцентами и диалектами.
- Понимание контекста произнесенных предложений.
- Разделение фоновых шумов для усиления качества входного сигнала.
- Переключение кода на разные языки для эффективной обработки.
- Анализ визуальных подсказок, используемых в речи в случае видеофайлов.
Транскрипция аудио и разработка искусственного интеллекта для преобразования речи в текст
Самая большая проблема с программным обеспечением для автоматического распознавания речи — это создание его вывода со 100% точностью. Поскольку необработанные данные являются динамическими и единый алгоритм не может быть применен, данные аннотируются, чтобы научить ИИ понимать их в правильном контексте.
Для выполнения этого процесса должны быть реализованы конкретные задачи, такие как:
 Распознавание именованных объектов (NER): ЧПО это процесс идентификации и сегментации различных именованных сущностей в определенные категории.
Распознавание именованных объектов (NER): ЧПО это процесс идентификации и сегментации различных именованных сущностей в определенные категории.- Анализ настроений и тем: Программное обеспечение, использующее несколько алгоритмов, проводит анализ настроений предоставленных данных, чтобы обеспечить безошибочные результаты.
 Распознавание именованных объектов (NER):
Распознавание именованных объектов (NER): - Анализ намерений и разговоров: Обнаружение намерений направлено на то, чтобы научить ИИ распознавать намерения говорящего. Он в основном используется для создания чат-ботов на базе искусственного интеллекта.
Заключение
В настоящее время технология преобразования речи в текст находится на большой стадии развития. Поскольку все больше цифровых устройств включают в свои приложения помощников по голосовому поиску и управлению, спрос на расшифровку аудио будет расти. Если вы заинтересованы в добавлении этой впечатляющей функции в свое приложение, свяжитесь со специалистами Shaip по сбору речевых данных, чтобы узнать все подробности.


